GNN-based Fashion Coordinator
1. About
1.1. Project Goal
-
Building a “Heterogeneous GNN model” using networkx and stellargraph
as a submission for Fashion-how Challenge, ETRI, 2021. -
Running GNN model on a cuda:GPU environment
Windows 11 > docker - ubuntu kernel > CUDA on WSL -
Data Reference:
Euisok Chung at al., “Dataset for Interactive Recommendation System”, HCLT-2020
1.2. Model Architecture
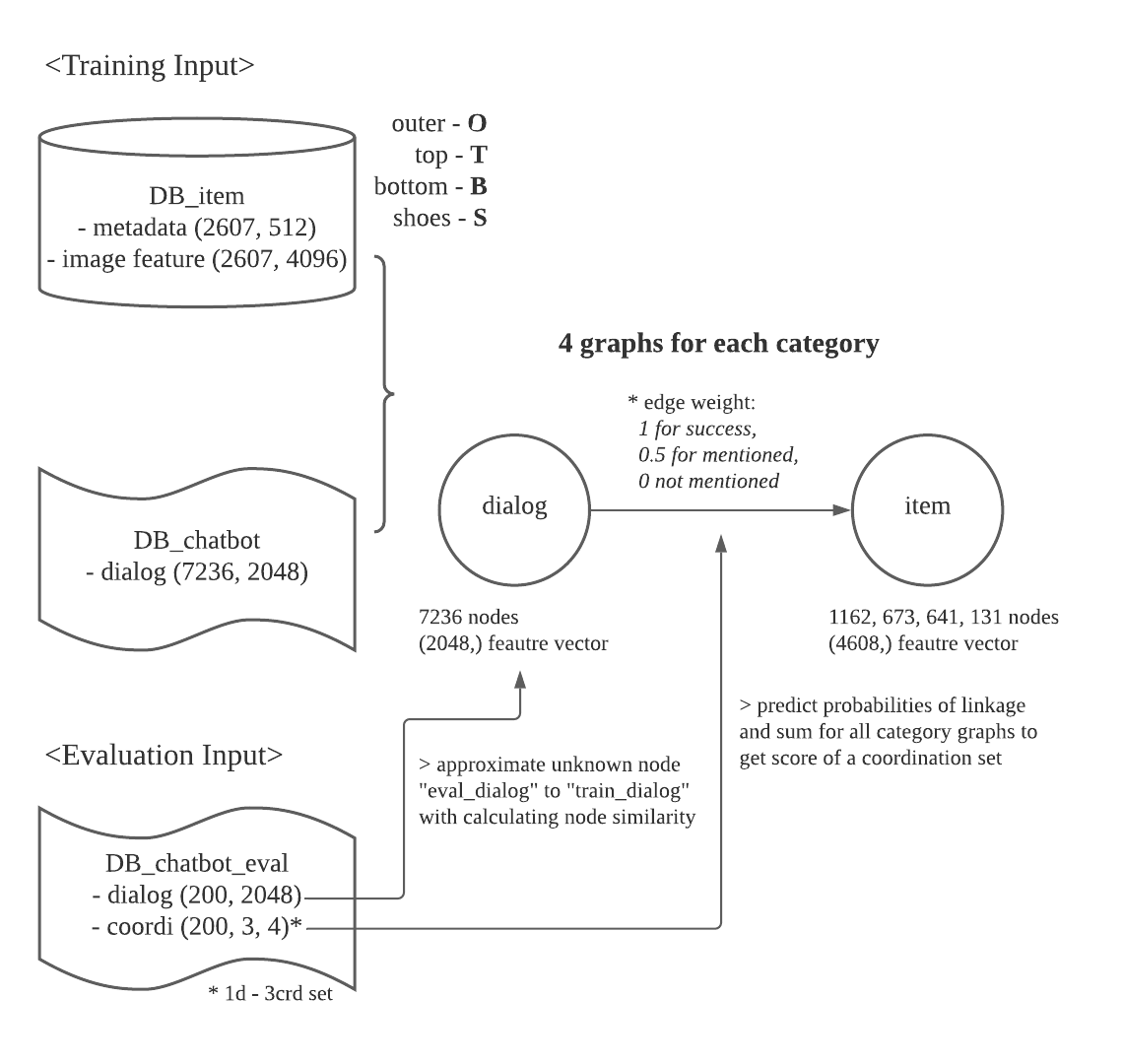
2. Load Data and Preprocess
# a sample of raw metadata DB
print(len(name),len(data_item))
print(name[0],data_item[:4]) # 4 descriptions for each item
2607 10428
BL-001
['단추 여밈 의 전체 오픈형 스탠드 칼라 와 브이넥 네크라인 의 결합 스타일 손목 까지 내려오 는 일자형 소매 여유로운 핏 어깨 에서 허리 까지 세로 절개 에 풍성 한 러플 장식 와이드 커프스',
'면 100% 구김 이 가 기 쉬운 드라이 클리닝 권장',
'시원_해 보이 는 소라색 SKY BLUE 단색 의 깔끔_한 느낌',
'여성 스러운 페미닌 한 세련 된 사랑 스러운 깔끔_한 오피스 룩 로맨틱 한 데이트 룩 포멀 한 이미지 단정 한 오피스 걸 룩 이미지']
[cat.shape for cat in g_model._metadata] # vectorized with pre-trained subword embedding
# [(1162, 512), (673, 512), (641, 512), (131, 512)]
[cat.shape for cat in g_model._feats] # vecotrized image features
# [(1162, 4096), (673, 4096), (641, 4096), (131, 4096)]
# in 4 categories, each items has 2 vectorized data, 512-length metadata & 4096-length imagedata
print(len(slot_name)) # 4
print(slot_name[0][0], slot_item[0][0].shape, slot_feat[0][0].shape)
# CD-001 (512,) (4096,)
[cat.shape for cat in g_model._meta_similarities]
# [(1162, 1162), (673, 673), (641, 641), (131, 131)]
from file_io_edit import _load_trn_dialog
dialog, coordi, reward, delim_dlg, delim_crd, delim_rwd = \
_load_trn_dialog(in_file_dialog)
print(len(dialog)) # all sentences in full dialogs
print(dialog[:21]) # example of the first dialog
92444
['어서 오 세 요 코디 봇 입 니다 무엇 을 도와 드릴_까 요',
'처음 대학교 들어가 는데 입 을 옷 코디 해 주 세 요',
'신입생 코디 에 어울리 게 화사 한 스웨터 를 추천_해 드릴_게 요',
'이 옷 에 어울리 는 치마 로 추천_해 주 세 요',
'고객 님 의 키 사이즈 에 맞추 면 이런 옷 도 잘 어울리 실 것 같_은데 어떠 신가 요',
'제 가 키 가 작_아서 짧 은 치마 로 추천_해 주 세 요',
'상의 색상 과 도 매칭 이 잘 어울리 는 짧 은 치마 입 니다',
'어두운 계열 은 없 나 요',
'언밸런스 한 컷팅 으로 세련미 를 돋보이 게_하 는 치마 인데 마음 에 드 시_나 요',
'나쁘 지_않 네 요 외투 도 추천_해 주 시 겠_어 요',
'요즘 계절 에는 가디건 이나 자켓 을 걸치기 에 좋_은데 특정 종류 로 원하 는 게 있 으신가 요',
'트렌치 코트 종류 로 추천_해 주 세 요',
'이너 색상 과 무난_하 게 잘 어울릴 트렌치 코트 입 니다',
'신발 도 추천_해 주 세 요',
'운동화 나 구두 중 어떤 걸 선호_하 시_나 요',
'운동화 로 추천_해 주 세 요',
'어떤 스타일 과 도 무난_하 게 잘 어울리 는 기본 아이템 입 니다',
'맘 에 드_네 요 전체 코디샷 볼_수 있 나 요',
'네 지금 까지 제안 해 드린 아이템 으로 전체 코디샷 을 제안 해 드립 니다 마음 에 드 시_나 요',
'네 마음 에 드_네 요 감사_합 니다',
'마음 에 드 신_다 니 다행 입 니다 이용_해 주 셔 서 감사_합 니다']
from file_io_edit import _episode_slice
dialog = _episode_slice(dialog, delim_dlg)
coordi = _episode_slice(coordi, delim_crd)
reward = _episode_slice(reward, delim_rwd)
print(len(dialog))
print(dialog[0]) # cut for each dialogs
7236
['어서 오 세 요 코디 봇 입 니다 무엇 을 도와 드릴_까 요',
'처음 대학교 들어가 는데 입 을 옷 코디 해 주 세 요',
'신입생 코디 에 어울리 게 화사 한 스웨터 를 추천_해 드릴_게 요',
'이 옷 에 어울리 는 치마 로 추천_해 주 세 요',
'고객 님 의 키 사이즈 에 맞추 면 이런 옷 도 잘 어울리 실 것 같_은데 어떠 신가 요',
'제 가 키 가 작_아서 짧 은 치마 로 추천_해 주 세 요',
'상의 색상 과 도 매칭 이 잘 어울리 는 짧 은 치마 입 니다',
'어두운 계열 은 없 나 요',
'언밸런스 한 컷팅 으로 세련미 를 돋보이 게_하 는 치마 인데 마음 에 드 시_나 요',
'나쁘 지_않 네 요 외투 도 추천_해 주 시 겠_어 요',
'요즘 계절 에는 가디건 이나 자켓 을 걸치기 에 좋_은데 특정 종류 로 원하 는 게 있 으신가 요',
'트렌치 코트 종류 로 추천_해 주 세 요',
'이너 색상 과 무난_하 게 잘 어울릴 트렌치 코트 입 니다',
'신발 도 추천_해 주 세 요',
'운동화 나 구두 중 어떤 걸 선호_하 시_나 요',
'운동화 로 추천_해 주 세 요',
'어떤 스타일 과 도 무난_하 게 잘 어울리 는 기본 아이템 입 니다',
'맘 에 드_네 요 전체 코디샷 볼_수 있 나 요',
'네 지금 까지 제안 해 드린 아이템 으로 전체 코디샷 을 제안 해 드립 니다 마음 에 드 시_나 요',
'네 마음 에 드_네 요 감사_합 니다',
'마음 에 드 신_다 니 다행 입 니다 이용_해 주 셔 서 감사_합 니다']
# vectorized dialog data
g_model._mem_trn_dlg.shape # (7236, 2048)
3. Initialize a Graph Model
- Procedure of loading and preprocessing data included
import random
random.seed(2021)
import numpy as np
np.random.seed(2021)
import tensorflow as tf
tf.random.set_seed(2021)
tf.device('/device:GPU:0')
import networkx as nx
import stellargraph as sg
import argparse
from graph_model import *
import os
g_model = graph_model(args)
<Initialize subword embedding>
loading= ./sstm_v0p5_deploy/sstm_v4p49_np_final_n36134_d128_r_eng_upper.dat
<Make metadata>
loading fashion item metadata
vectorizing data
<Make input & output data>
loading dialog DB
# of dialog: 7236 sets
vectorizing data
memorizing data
<Make input & output data>
loading dialog DB
# of dialog: 200 sets
vectorizing data
memorizing data
3.1. Generate graphs and edge data for each item categories
g_model._graph_cats
(<stellargraph.core.graph.StellarGraph at 0x7f58a4f11bb0>,
<stellargraph.core.graph.StellarGraph at 0x7f58a4f11f10>,
<stellargraph.core.graph.StellarGraph at 0x7f58a4f11c40>,
<stellargraph.core.graph.StellarGraph at 0x7f58a4758af0>)
for g in g_model._graph_cats:
print(g.info())
StellarGraph: Undirected multigraph
Nodes: 8398, Edges: 9222
Node types:
dialog: [7236]
Features: float32 vector, length 2048
Edge types: dialog-default->item
item: [1162]
Features: float32 vector, length 4608
Edge types: item-default->dialog
Edge types:
dialog-default->item: [9222]
Weights: range=[0.5, 1], mean=0.607623, std=0.205508
Features: none
StellarGraph: Undirected multigraph
Nodes: 7909, Edges: 9022
Node types:
dialog: [7236]
Features: float32 vector, length 2048
Edge types: dialog-default->item
item: [673]
Features: float32 vector, length 4608
Edge types: item-default->dialog
Edge types:
dialog-default->item: [9022]
Weights: range=[0.5, 1], mean=0.607515, std=0.205433
Features: none
StellarGraph: Undirected multigraph
Nodes: 7877, Edges: 11549
Node types:
dialog: [7236]
Features: float32 vector, length 2048
Edge types: dialog-default->item
item: [641]
Features: float32 vector, length 4608
Edge types: item-default->dialog
Edge types:
dialog-default->item: [11549]
Weights: range=[0.5, 1], mean=0.613733, std=0.209607
Features: none
StellarGraph: Undirected multigraph
Nodes: 7367, Edges: 9757
Node types:
dialog: [7236]
Features: float32 vector, length 2048
Edge types: dialog-default->item
item: [131]
Features: float32 vector, length 4608
Edge types: item-default->dialog
Edge types:
dialog-default->item: [9757]
Weights: range=[0.5, 1], mean=0.618479, std=0.212619
Features: none
g_model._graph_datas[0]
| dialog | item | label | |
|---|---|---|---|
| 0 | d_2 | o_0 | 1.0 |
| 1 | d_53 | o_0 | 1.0 |
| 2 | d_133 | o_0 | 0.5 |
| 3 | d_337 | o_0 | 0.5 |
| 4 | d_437 | o_0 | 0.5 |
| ... | ... | ... | ... |
| 9217 | d_5649 | o_1160 | 0.5 |
| 9218 | d_5938 | o_1160 | 0.5 |
| 9219 | d_5972 | o_1160 | 1.0 |
| 9220 | d_6439 | o_1160 | 0.5 |
| 9221 | d_6788 | o_1160 | 0.5 |
9222 rows × 3 columns
g_model._graph_datas[1]
| dialog | item | label | |
|---|---|---|---|
| 0 | d_514 | t_0 | 0.5 |
| 1 | d_560 | t_0 | 0.5 |
| 2 | d_815 | t_0 | 0.5 |
| 3 | d_839 | t_0 | 0.5 |
| 4 | d_884 | t_0 | 0.5 |
| ... | ... | ... | ... |
| 9017 | d_5905 | t_672 | 1.0 |
| 9018 | d_5919 | t_672 | 0.5 |
| 9019 | d_5999 | t_672 | 0.5 |
| 9020 | d_6745 | t_672 | 1.0 |
| 9021 | d_6746 | t_672 | 0.5 |
9022 rows × 3 columns
g_model._graph_datas[2]
| dialog | item | label | |
|---|---|---|---|
| 0 | d_34 | b_0 | 0.5 |
| 1 | d_225 | b_0 | 0.5 |
| 2 | d_272 | b_0 | 1.0 |
| 3 | d_302 | b_0 | 1.0 |
| 4 | d_380 | b_0 | 0.5 |
| ... | ... | ... | ... |
| 11544 | d_6239 | b_637 | 0.5 |
| 11545 | d_6379 | b_637 | 0.5 |
| 11546 | d_5506 | b_638 | 0.5 |
| 11547 | d_5576 | b_638 | 0.5 |
| 11548 | d_5097 | b_639 | 1.0 |
11549 rows × 3 columns
g_model._graph_datas[3]
| dialog | item | label | |
|---|---|---|---|
| 0 | d_47 | s_0 | 0.5 |
| 1 | d_52 | s_0 | 0.5 |
| 2 | d_74 | s_0 | 0.5 |
| 3 | d_124 | s_0 | 0.5 |
| 4 | d_175 | s_0 | 0.5 |
| ... | ... | ... | ... |
| 9752 | d_6643 | s_129 | 0.5 |
| 9753 | d_6684 | s_129 | 0.5 |
| 9754 | d_7050 | s_129 | 1.0 |
| 9755 | d_7082 | s_129 | 0.5 |
| 9756 | d_7124 | s_129 | 1.0 |
9757 rows × 3 columns
4. Model Training
4.1. Load Evaluation Data
np.array(g_model._mem_tst_dlg).shape # (200, 2048)
np.array(g_model._tst_crd).shape # (200, 3, 4)
4.2. Train with HinSAGE and Link Prediction Error
- work on building a base model, not fully optimized
...
# training function
def _graph_train(self,data,data_graph):
batch_size = 200
epochs = 10
train_size = 0.7
test_size = 0.3
num_samples = [8, 4]
num_workers = 2
edges_train, edges_test = model_selection.train_test_split(data, train_size=train_size, test_size=test_size)
edgelist_train = list(edges_train[["dialog", "item"]].itertuples(index=False))
edgelist_test = list(edges_test[["dialog", "item"]].itertuples(index=False))
labels_train = edges_train["label"]
labels_test = edges_test["label"]
generator = HinSAGELinkGenerator(
data_graph, batch_size, num_samples, head_node_types=["dialog", "item"])
train_gen = generator.flow(edgelist_train, labels_train, shuffle=True)
test_gen = generator.flow(edgelist_test, labels_test)
hinsage_layer_sizes = [32, 32]
assert len(hinsage_layer_sizes) == len(num_samples)
hinsage = HinSAGE(
layer_sizes=hinsage_layer_sizes, generator=generator, bias=True, dropout=0.0)
x_inp, x_out = hinsage.in_out_tensors()
score_prediction = link_regression(edge_embedding_method="concat")(x_out)
model = Model(inputs=x_inp, outputs=score_prediction)
model.compile(
optimizer=optimizers.Adam(learning_rate=1e-2),
loss=losses.mean_squared_error,
metrics=[root_mean_square_error, metrics.mae],)
test_metrics = model.evaluate(
test_gen, verbose=1, use_multiprocessing=False, workers=num_workers
)
history = model.fit(
train_gen,
validation_data=test_gen,
epochs=epochs,
verbose=1,
shuffle=False,
use_multiprocessing=False,
workers=num_workers,)
test_metrics = model.evaluate(
test_gen, use_multiprocessing=False, workers=num_workers, verbose=1)
print("Test Evaluation:")
for name, val in zip(model.metrics_names, test_metrics):
print("\t{}: {:0.4f}".format(name, val))
y_true = labels_test
y_pred = model.predict(test_gen)
y_pred_baseline = np.full_like(y_pred, np.mean(y_true))
...
g_model.train()
link_regression: using 'concat' method to combine node embeddings into edge embeddings
14/14 [==============================] - 3s 92ms/step - loss: 0.1245 - root_mean_square_error: 0.3521 - mean_absolute_error: 0.2666
Untrained model's Test Evaluation:
loss: 0.1245
root_mean_square_error: 0.3521
mean_absolute_error: 0.2666
Epoch 1/10
33/33 [==============================] - 8s 222ms/step - loss: 0.0947 - root_mean_square_error: 0.2792 - mean_absolute_error: 0.2281 - val_loss: 0.0451 - val_root_mean_square_error: 0.2123 - val_mean_absolute_error: 0.1991
Epoch 2/10
33/33 [==============================] - 7s 217ms/step - loss: 0.0441 - root_mean_square_error: 0.2093 - mean_absolute_error: 0.1761 - val_loss: 0.0427 - val_root_mean_square_error: 0.2062 - val_mean_absolute_error: 0.1558
Epoch 3/10
33/33 [==============================] - 8s 226ms/step - loss: 0.0426 - root_mean_square_error: 0.2062 - mean_absolute_error: 0.1684 - val_loss: 0.0423 - val_root_mean_square_error: 0.2053 - val_mean_absolute_error: 0.1613
Epoch 4/10
33/33 [==============================] - 8s 224ms/step - loss: 0.0425 - root_mean_square_error: 0.2053 - mean_absolute_error: 0.1683 - val_loss: 0.0422 - val_root_mean_square_error: 0.2050 - val_mean_absolute_error: 0.1620
Epoch 5/10
33/33 [==============================] - 8s 234ms/step - loss: 0.0423 - root_mean_square_error: 0.2053 - mean_absolute_error: 0.1679 - val_loss: 0.0425 - val_root_mean_square_error: 0.2058 - val_mean_absolute_error: 0.1805
Epoch 6/10
33/33 [==============================] - 8s 231ms/step - loss: 0.0423 - root_mean_square_error: 0.2057 - mean_absolute_error: 0.1682 - val_loss: 0.0420 - val_root_mean_square_error: 0.2047 - val_mean_absolute_error: 0.1751
Epoch 7/10
33/33 [==============================] - 8s 233ms/step - loss: 0.0421 - root_mean_square_error: 0.2046 - mean_absolute_error: 0.1701 - val_loss: 0.0417 - val_root_mean_square_error: 0.2039 - val_mean_absolute_error: 0.1685
Epoch 8/10
33/33 [==============================] - 8s 229ms/step - loss: 0.0421 - root_mean_square_error: 0.2050 - mean_absolute_error: 0.1662 - val_loss: 0.0415 - val_root_mean_square_error: 0.2033 - val_mean_absolute_error: 0.1686
Epoch 9/10
33/33 [==============================] - 8s 238ms/step - loss: 0.0415 - root_mean_square_error: 0.2036 - mean_absolute_error: 0.1679 - val_loss: 0.0411 - val_root_mean_square_error: 0.2025 - val_mean_absolute_error: 0.1695
Epoch 10/10
33/33 [==============================] - 8s 232ms/step - loss: 0.0411 - root_mean_square_error: 0.2023 - mean_absolute_error: 0.1668 - val_loss: 0.0409 - val_root_mean_square_error: 0.2017 - val_mean_absolute_error: 0.1535
14/14 [==============================] - 2s 121ms/step - loss: 0.0408 - root_mean_square_error: 0.2016 - mean_absolute_error: 0.1535
Test Evaluation:
loss: 0.0408
root_mean_square_error: 0.2016
mean_absolute_error: 0.1535
Mean Baseline Test set metrics:
root_mean_square_error = 0.2054230809528016
mean_absolute_error = 0.1687945779971711
Model Test set metrics:
root_mean_square_error = 0.20211308444911932
mean_absolute_error = 0.15357324988306925
...
...
...
Done training
from numba import cuda
device = cuda.get_current_device()
device.reset()