Mask R-CNN
Mask R-CNN
Kaiming He, Georgia Gkioxari, Piotr Dollár, Ross Girshick, ICCV 2017
https://github.com/facebookresearch/Detectron
What’s different?
-
Models so far
R-CNN: 2-stage model for Object detection
Fast R-CNN: RoI on feature map
Faster R-CNN: RPN network - Instance Segmentation
Combining to tasks:- Object detection(Fast/Faster R-CNN): classify individual objects and localize each using a bounding box.
- Semantic segmentation(FCN; Fully Convolutional Network): classify each pixel into a fixed set of categories without differentiating object instances.
- Mask R-CNN:
1) Model for instance segmentation: Mask prediction branch
2) FPN(feature pyramid network) before RPN
3) RoI align
Mask prediction
-
Mask loss
In the second stage, in parallel to predicting the class and box offset, Mask R-CNN also outputs a binary mask(ones to the object and zeros elsewhere) for each RoI. Defined multi-task loss on each sampled RoI: $L = L_{cls} + L_{box} + L_{mask}$
The mask branch has a $Km^2$-dimensional output for each RoI, which encodes K binary masks of resolution $m\times m$, one for each of the K classes. To this we apply a per-pixel sigmoid, and define $L_{mask}$ as the average binary cross-entropy loss. For an RoI associated with ground-truth class k, $L_{mask}$ is only defined on the k-th mask(other mask outputs do not contribute to the loss). -
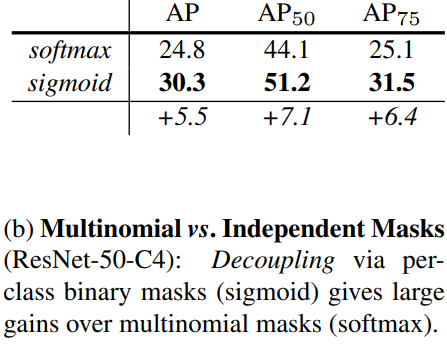
Decouples mask and class prediction
This definition of mask loss allows the network to generate masks for each class without competition among classes; we rely on the dedicated classification branch to predict the class label used to select the output mask.
With a per-pixel sigmoid and a binary loss, masks do not compete across classes; in contrast to FCNs for semantic segmentation using a per-pixel softmax and a multinomial cross-entropy loss. -
Mask Representation
Unlike class labels or box offsets, extracting the spatial structure of masks can be addressed naturally by the pixel-to-pixel correspondence provided by convolutions.
Predicting an $m\times m$ mask from each RoI using an FCN, allows each layer in the mask branch to have $m\times m$ object spatial layout without collapsing it into a vector representation that lacks spatial dimensions.
This pixel-to-pixel behavior requires RoI features, small cropped feature maps, to be well aligned to faithfully preserve the explicit per-pixel spatial correspondence; RoIAlign.
RoIAlign
- RoIPool(or RoI Pooling)
Quantizes a floating-number RoI to the discrete granularity(integerize by rounding) of the feature map, its result is then subdivided into spatial bins, and finally feature values covered by each bin are aggregated(usually by max pooling).- Problem: Quantizations introduce misalignments between the RoI and the extracted features. This may not impact classification, which is robust to small translations, but it has a large negative effect on predicting pixel-accurate masks.
-
RoIAlign layer
Instead of any quantization of the RoI boundaries or bins, use bilinear interpolation(Spatial transformer networks) to compute the exact values of the input features at four regularly sampled locations in each RoI bin, and aggregate the result(using max or average).
e.g.
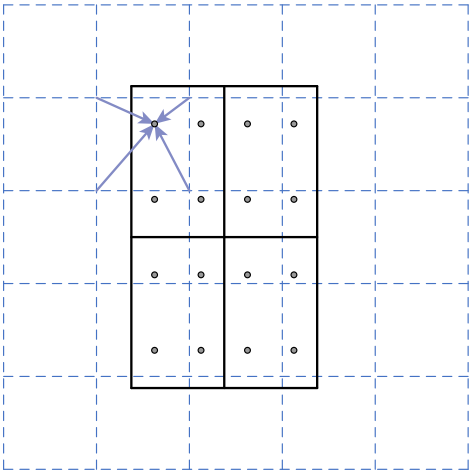
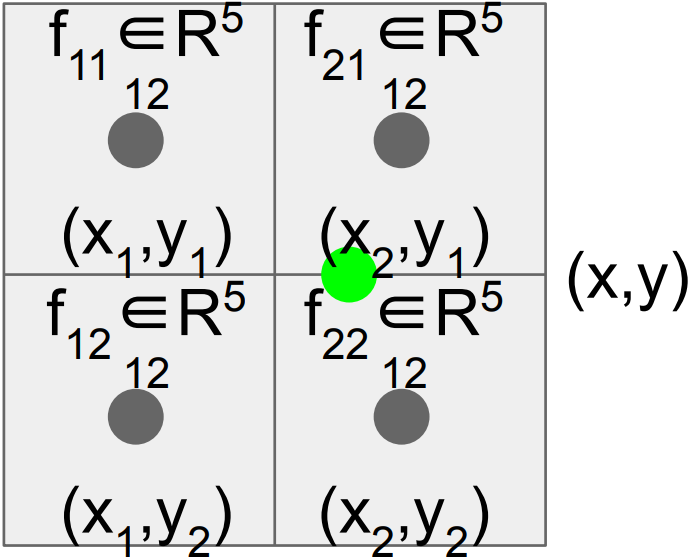
(from CS231n lecture)
Feature $f_{xy}$ for point $(x, y)$ is a linear combination of features at its four neighboring grid cells:
$f_{xy} = \sum_{i,j=1}^2 f_{i,j} \text{max}(0, 1 - \left\vert x - x_i \right\vert) \text{max}(0, 1 - \left\vert y - y_i \right\vert)$ - RoIAlign improves mask accuracy by relative 10% to 50%, showing bigger gains under stricter localization metrics.
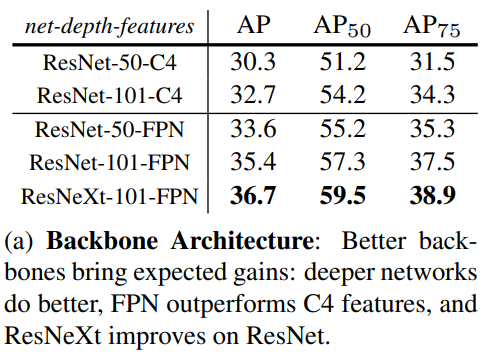
Network Architecture
- backbone: Faster R-CNN with an FPN(ResNet-FPN)
- FPN, Feature pyramid network(Lin et al.):
Uses a top-down architecture with lateral connections to build an in-network feature pyramid from a single-scale input. - RPN:
RoI align on each FPN feature maps
- FPN, Feature pyramid network(Lin et al.):
- head:
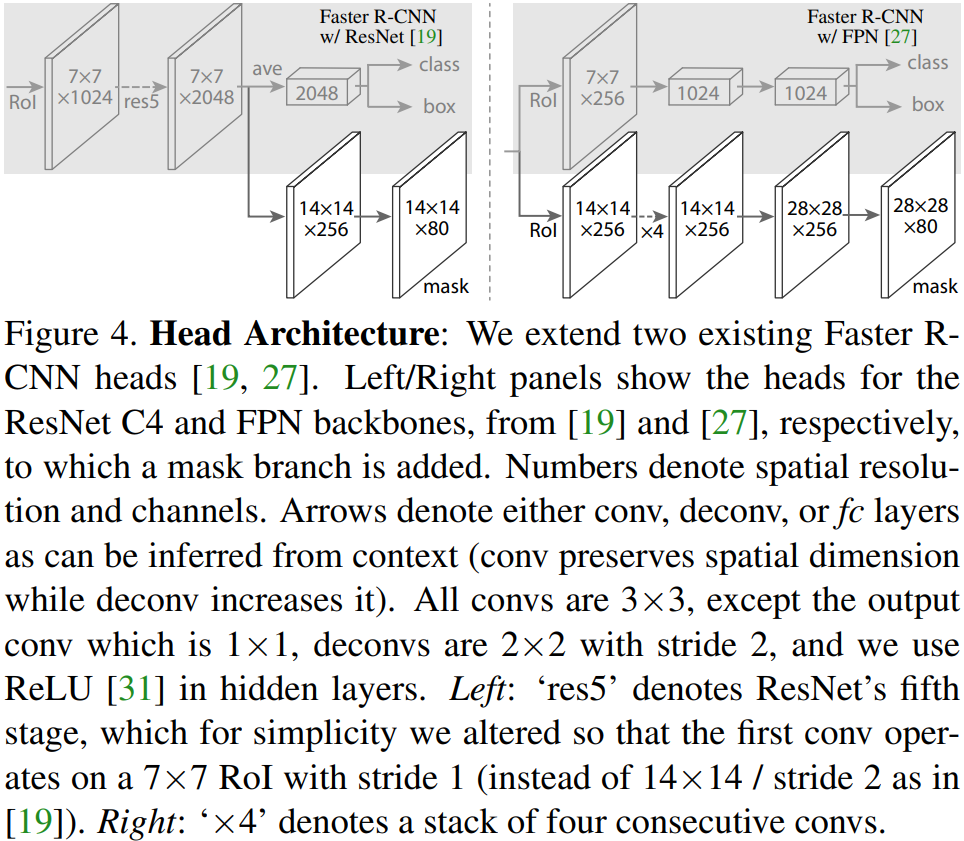
Add a fully convolutional mask prediction branch, extending the Faster R-CNN box heads from the ResNet and FPN papers. Train with additional mask loss.
Experiments
- Comparison to the sota methods in instance segmentation
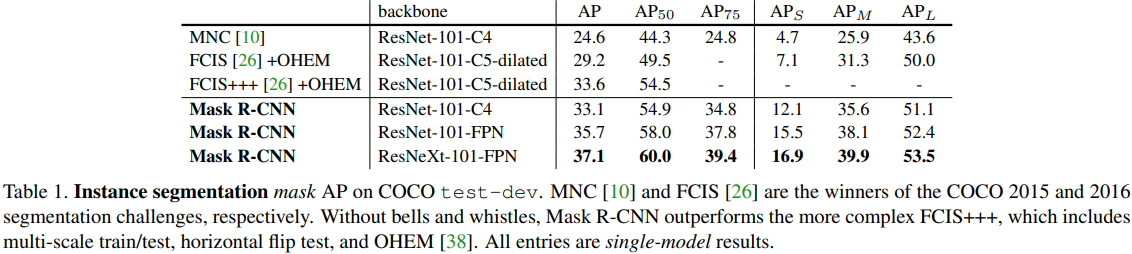

- Ablations
- Architecture
- Multinomial vs. Independent Masks
- Class-Specific vs. Class-Agnostic Masks
Interestingly, Mask R-CNN with classagnostic masks(predicting a single m×m output regardless of class)) is nearly as effective as class-specific masks(default; m×m mask per class). - RoIAlign
ResNet50-C4 backbone of stride 16

ResNet-50-C5 backbone of stride 32
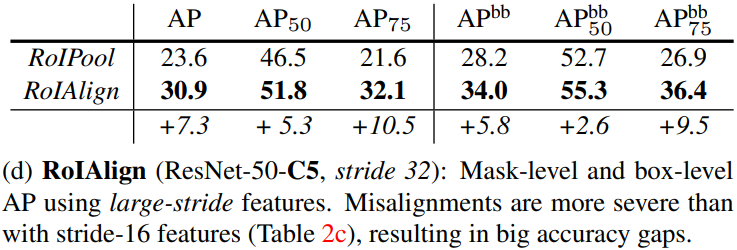
Note that with RoIAlign, using stride-32 C5 features is more accurate than using stride-16 C4 features. Used with FPN, which has finer multi-level strides, RoIAlign shows better result. - Mask branch

- Architecture
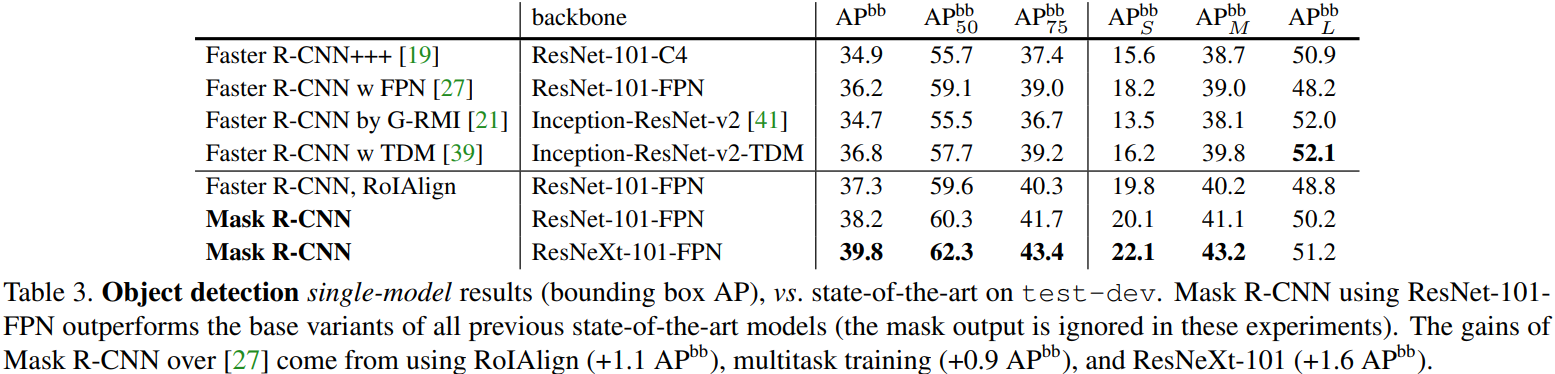
- Bounding Box Detection Results
Our approach largely closes the gap between object detection and the more challenging instance segmentation task.
Mask R-CNN for Human Pose Estimation
-
By modeling a keypoint’s location as a one-hot mask, and adopt Mask R-CNN to predict K masks, one for each of K keypoint types, this framework can easily be extended to human pose estimation.
-
Main Results and Ablations:
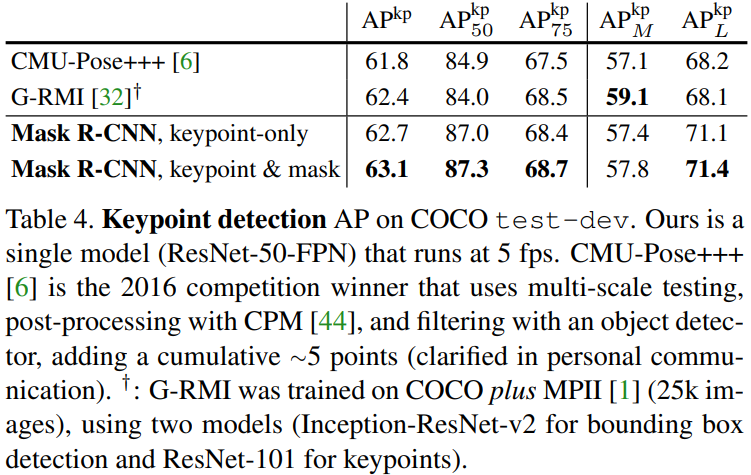
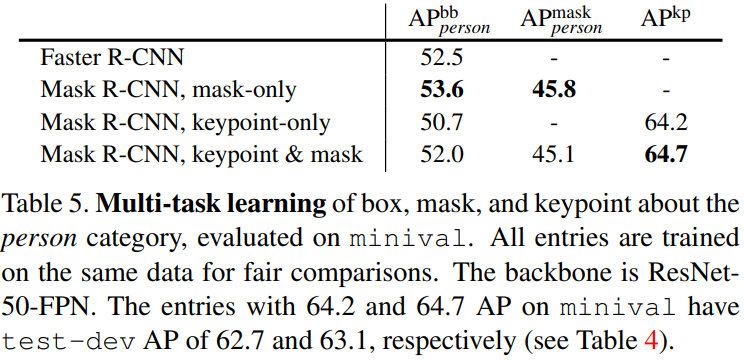

$\therefore$ We have a unified model that can simultaneously predict boxes, segments, and keypoints while running at 5 fps.