Unsupervised Representation Learning by Predicting Image Rotations
Unsupervised Representation Learning by Predicting Image Rotations
Gidaris et al. 2018
https://github.com/gidariss/FeatureLearningRotNet
- ConvNet:
(+) Unparalleled capacity to learn high level semantic image features
(-) Require massive amounts of manually labeled data, expensive and impractical to scale
$\rightarrow$ Unsupervised Learning - Unsupervised semantic feature learning:
Learn image features by training ConvNets to recognize the 2d rotated images as input. With apparently simple task, provides a very powerful supervisory signal for semantic feature learning(Conv). Evaluated in various unsupervised feature learning benchmarks, exceeds SotA performance.
FeatureLearningRotNet
- How To:
First define a small set of discrete geometric transformations, then each of those transformations are applied to each image on the dataset and produced transformed images are fed to ConvNet model that is trained to recognize the transformation of each image.- Set of geometric transformations define the classification pretext task that the ConvNet has to learn; to achieve unsupervised semantic feature learning, it is important to properly choose those geometric transformations.
-
Purpose: to define the geometric transformations as rotations of 4 different degrees, ConvNet trained on the 4-way image classification task of recognizing one of the four Maximizing prob. $F^y(x^{y^{*}})$, probability of transformation y predicted by F, when given X is transformed by the transformation $y^{*}$.
- With idea: In order a ConvNet model to be able recognize the rotation transformations, it will require to understand the concept of the objects depicted in the image such as their location, type, and pose.
Overview
- define a set of K discrete geometric transformations \(G = \{g(\cdot\vert y)\}_{y=1}^K\), where $g(.\vert y)$ applies to input X, transformed image $X^y = g(X\vert y)$
- ConvNet model F(.) gets as input an image $X^{y^{\ast}}$, to recognize unknown $y^{\ast}$ yields as output a probability distribution over all possible transformations \(F(X^{y^{\ast}}\vert\theta) = \{ F^y(X^{y^{\ast}}\vert\theta) \}_{y=1}^K\), output F returns probs for all classes $y$.
- Therefore, N training images \(D = \{ X_i \}_{i=0}^N\), the self-supervised training objective that ConvNet must learn to solve is:
\(\mbox{min}_{\theta}\frac{1}{N}\sum_{i=1}^N \mbox{loss}(X_i,\theta)\),
where the loss function is defined as:
\(\mbox{loss}(X_i,\theta) = -\frac{1}{K}\sum_{y=1}^K \log(F^y(g(X_i|y)|\theta))\)
(negative sum of log probs F for all classes y)
- 2d image rotations:
$Rot(X, \phi)$, operator that rotates image X by $\phi$ degrees
In this case 0, 90, 180, 270; K=4 for G, where $g(X|y)=Rot(X,(y-1)90)$
Forcing the learning of semantic features
Fact that it is essentially impossible for a ConvNet model to effectively perform the above rotation recognition task, unless it has first learnt to recognize and detect classes of objects as well as their semantic parts in images.
$\rightarrow$ ATTENTION MAPS

- By comparing the attention maps from two models trained on supervised and unsupervised way, we observe that both models seem to focus on roughly the same image regions.

- Also, trained on the proposed rotation recognition task, visualized layer filters learnt appear to have a big variety of edge filters on multiple orientations and multiple frequencies, then the filters learnt by the supervised task.
- Absence of low-level visual artifacts:
An additional important advantage of using image rotations over other geometric transformations, is that they do not leave e any easily detectable low-level visual artifacts that will lead the ConvNet to learn trivial features with no practical value for the vision perception tasks. - Well-posedness:
Human captured images tend to depict objects in an “up-standing” position. When defining the rotation recognition task, there is usually no ambiguity of what is the rotation transformation. - Implementing image rotations:
Flip and transpose.
- Absence of low-level visual artifacts:
- $*$ Activation-based Attention Maps from “Paying More Attention to Attention”, Zagoruyko et al., 2017 - https://arxiv.org/abs/1612.03928
Activation tensor of a conv. layer: $A\in R^{C\times H\times W}$ consists of C feautre planes with spatial dimensions HxW
Activation-based mapping function F w.r.t that layer: $\mathcal{F}: R^{C\times H\times W} \rightarrow R^{H\times W}$
With implicit assumption: Absolute value of a hidden neuron activation(that results when the network is evaluated on given input) can be used as an indication about the importance of that neuron w.r.t. the specific input.
By considering, therefore, the absolute values of the elements of tensor A, we construct a spatial attention map by computing statistics of these values across the channel dimension(C)- sum of abs: $F_{sum}(A)=\sum_{i=1}^C\vert A_i\vert$
- sum of abs, raised to the power of p(>1): $F_{sum}^p(A) = \sum_{i=1}^C\vert A_i\vert^p$
- max of abs, raised to the pwoer of p(>1): $F_{max}^p(A) = \mbox{max}_{i=1,C}\vert A_i\vert^p$
Transfer Learning
With a model trained on proposed rotation recognition task with unlabeled data, freeze its early conv. layers and attach the layers from a supervised model, evaluate on a supervised task with a subset of labeled data.
Experimental Results
CIFAR-10 Experiments
-
RotNet implementation details:
Network-In-Network (NIN) architectures (Lin et al., 2013)
Pretask train:optimizer = SGD, batch_size = 128, momentum = 0.9, weight_decay = 5e−4, lr = 0.1, lr_decay = 0.2 (after 30, 60, 80 epochs), num_epochs = 100 - Evaluation of the learned feature hierarchies:
Using the CIFAR-10 training images, train three RotNet models which have 3, 4, and 5 conv. blocks respectively. Afterwards, on top of the feature maps generated by each conv. block of each RotNet model, add classifiers trained in a supervised way on the object recognition task of CIFAR-10; consists of 3 FC layers. The accuracy results of CIFAR-10 test set:
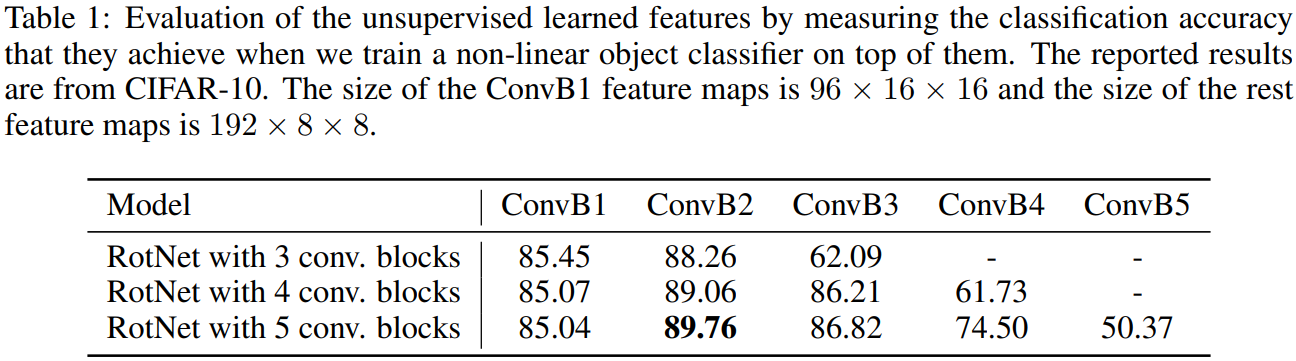
- In all cases the feature maps generated by the 2nd conv. block achieve the highest accuracy, i.e., between 88.26% and 89.06%. Then the accuracy gradually degrades, which we assume is because they start becoming more and more specific on the self-supervised task of rotation prediction.
- Observe that increasing the total depth of the RotNet models leads to increased object recognition performance by the feature maps generated by earlier layers. We assume that this is because increasing the depth of the model and thus the complexity of its head (i.e., top ConvNet layers) allows the features of earlier layers to be less specific to the rotation prediction task.
- Exploring the quality of the learned features w.r.t. the number of recognized rotations:

- Observed that 4 discrete rotations as proposed achieved better performance over other cases.
- Comparison against supervised and other unsupervised methods:
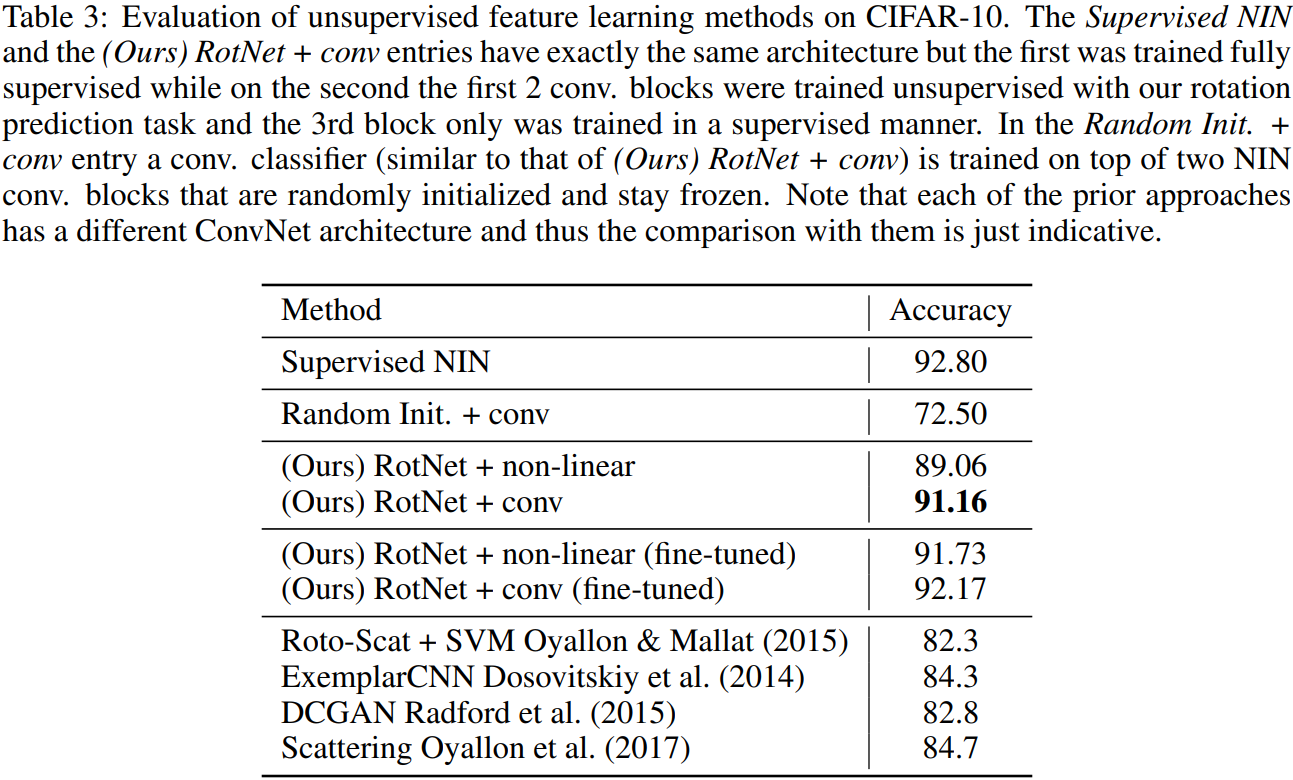

- Model using the feature maps generated by the 2nd conv. block of a RotNet model with 4 conv. blocks in total.
(a) RotNet + non-linear: a non-linear classifier with 3 fully connected layers
(b) RotNet +conv.: three conv. layers + a linear prediction layer - Achieved best result among the unsupervised approaches
- Very close to the fully supervised NIN model
- Observed that fine-tuning the unsupervised learned features further improves the classification performance
- Model using the feature maps generated by the 2nd conv. block of a RotNet model with 4 conv. blocks in total.
- Correlation between object classification task and rotation prediction task:
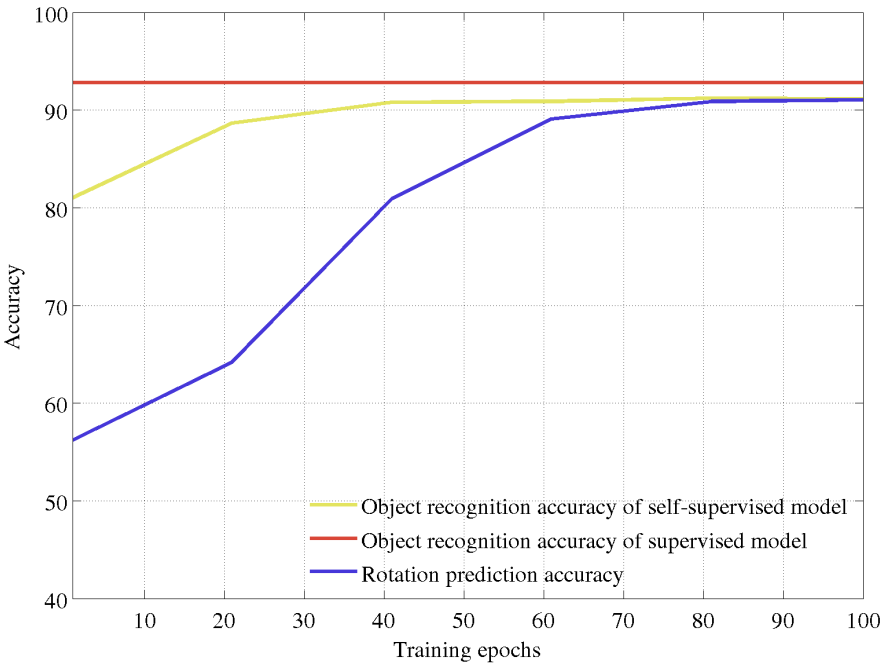
- As the ability of the RotNet features for solving the rotation prediction task improves(as the rotation prediction accuracy increases), their ability to help solving the object recognition task improves as well(the object recognition accuracy also increases).
- Object recognition accuracy converges fast w.r.t. the number of training epochs used for solving the pretext task of rotation prediction.
- Semi-supervised setting:
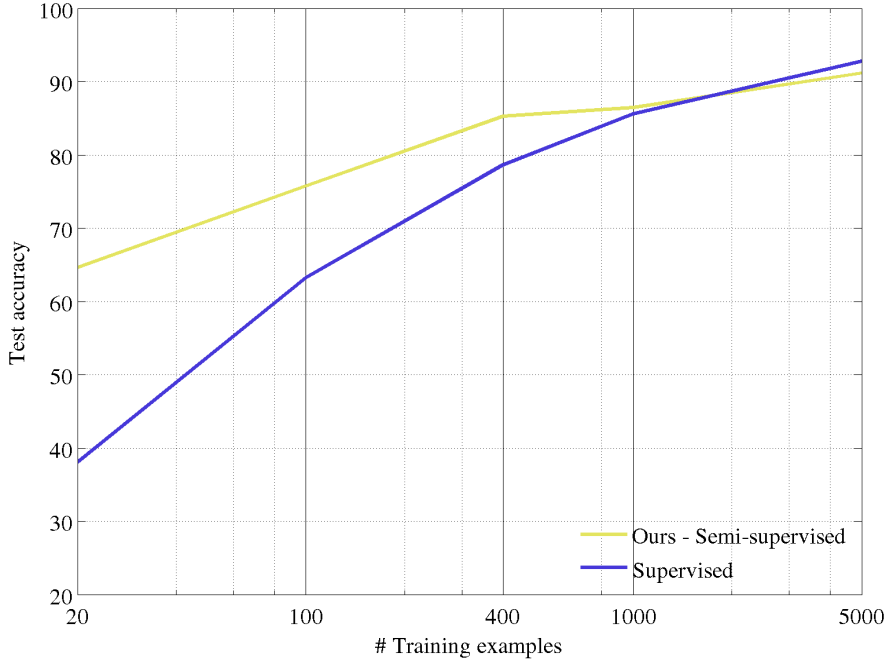
Train a 4 block RotNet model on the rotation prediction task using the entire image dataset of CIFAR-10, then train on top of its feature maps object classifiers using only a subset of the available images and their corresponding labels. As feature maps we use those from 2nd conv. block of the RotNet model. As a classifier we use a set of convolutional layers of the same e architecture as the 3rd conv. block of a NIN model plus a linear classifier, all randomly initialized. For training the object classifier we use for each category 20, 100, 400, 1000, or 5000 image examples. Comapred with a supervised model that is trained only on the available examples each time:- Observed that our unsupervised trained model exceeds in this semi-supervised setting the supervised model when the number of examples per category drops below 1000; can be useful when there are only small subset of labeled data.
Evaluation of self-supervised features trained in ImageNet
-
Train a RotNet model on the training images of the ImageNet dataset and evaluate the performance of the self-self-supervised features on the image classification tasks of ImageNet, Places, and PASCAL VOC datasets and on the object detection and object segmentation tasks of PASCAL VOC.
-
Implementation details:
Based on an AlexNet architecture, without local response normalization units, dropout units, or groups in the colvolutional layers, while it includes batch normalization units after each linear layer (either convolutional or fully connected).
Train withSGD, batch_size=192, momentum=0.9, weight_decay=5e-4, lr=0.01, lr_decay=0.1(after 10, 20 epochs), num_epochs=30 - ImageNet classification task:
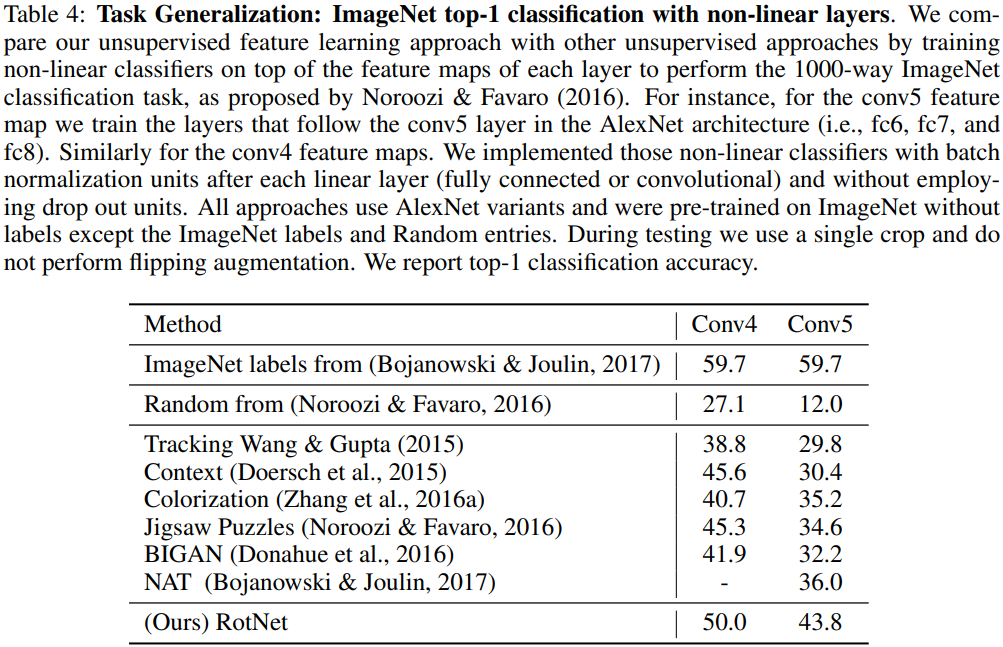
- Observed that our approach surpasses all the other methods by a significant margin
- Transfer learning evaluation on PASCAL VOC:
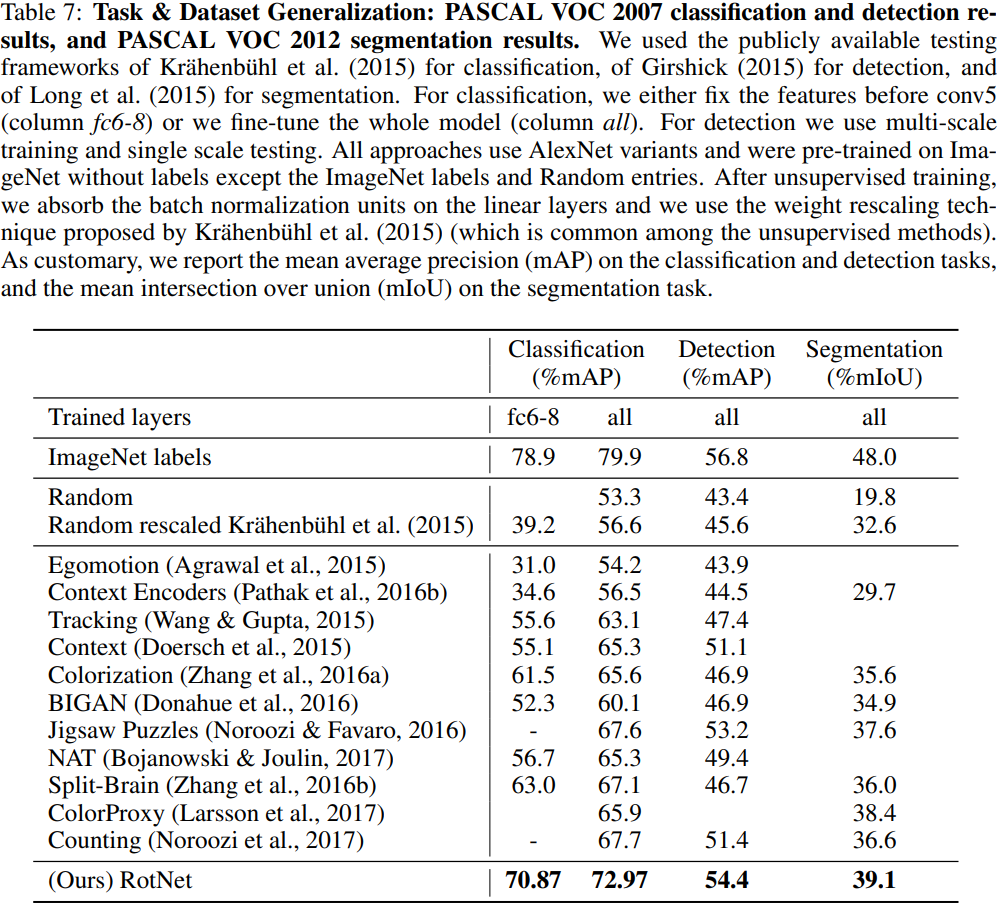
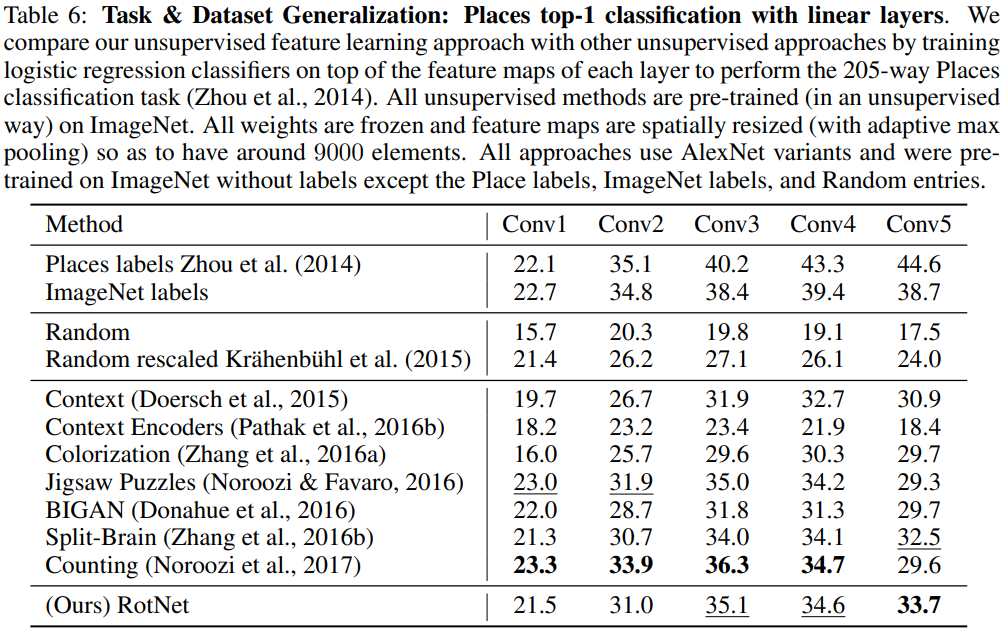
- Places classification task: