Stock Market Cluster Analysis with NetworkX
1. Data Load and Preprocessing
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.collections import LineCollection
from sklearn import cluster, covariance, manifold
from community import community_louvain as louvain
import matplotlib.cm as cm
import networkx as nx
import networkx.algorithms.community as nxcom
from importlib import reload
import csv
import os
import re
%matplotlib inline
df_prices = pd.read_csv("SP500_prices.csv", index_col = 0)
df_indices = pd.read_csv("indices.csv")
df_SP500 = pd.read_csv("SP500.csv",index_col = 0)
df_prices.describe()
| open | high | low | close | volume | adjusted | |
|---|---|---|---|---|---|---|
| count | 282821.000000 | 282821.000000 | 282821.000000 | 282821.000000 | 2.828210e+05 | 282821.000000 |
| mean | 139.384227 | 141.184891 | 137.569435 | 139.425703 | 4.983235e+06 | 137.510842 |
| std | 249.635882 | 253.080583 | 246.310869 | 249.739199 | 1.180107e+07 | 249.704273 |
| min | 3.220000 | 3.290000 | 3.020000 | 3.120000 | 0.000000e+00 | 3.092542 |
| 25% | 47.780000 | 48.419998 | 47.120000 | 47.790001 | 1.010000e+06 | 46.309925 |
| 50% | 86.430000 | 87.480003 | 85.320000 | 86.420000 | 2.034800e+06 | 84.330002 |
| 75% | 151.500000 | 153.380005 | 149.600006 | 151.570000 | 4.528900e+06 | 148.930000 |
| max | 4742.610000 | 4832.800000 | 4700.000000 | 4776.410000 | 4.286171e+08 | 4776.410000 |
df_prices.head()
| symbol | date | open | high | low | close | volume | adjusted | |
|---|---|---|---|---|---|---|---|---|
| 1 | AAPL | 2019-01-02 | 38.722500 | 39.712502 | 38.557499 | 39.480000 | 148158800.0 | 38.505024 |
| 2 | AAPL | 2019-01-03 | 35.994999 | 36.430000 | 35.500000 | 35.547501 | 365248800.0 | 34.669640 |
| 3 | AAPL | 2019-01-04 | 36.132500 | 37.137501 | 35.950001 | 37.064999 | 234428400.0 | 36.149662 |
| 4 | AAPL | 2019-01-07 | 37.174999 | 37.207500 | 36.474998 | 36.982498 | 219111200.0 | 36.069202 |
| 5 | AAPL | 2019-01-08 | 37.389999 | 37.955002 | 37.130001 | 37.687500 | 164101200.0 | 36.756794 |
df_prices_adj = df_prices[['symbol','date', 'adjusted']]
df_prices_adj.columns = ['symbol','date','price']
df_prices_adj.tail()
| symbol | date | price | |
|---|---|---|---|
| 282817 | NWS | 2021-03-24 | 23.69 |
| 282818 | NWS | 2021-03-25 | 24.42 |
| 282819 | NWS | 2021-03-26 | 24.01 |
| 282820 | NWS | 2021-03-29 | 23.39 |
| 282821 | NWS | 2021-03-30 | 23.83 |
df_indices.describe()
| Unnamed: 0 | price | |
|---|---|---|
| count | 16385.000000 | 16215.000000 |
| mean | 8193.000000 | 588.995521 |
| std | 4730.086416 | 3309.895206 |
| min | 1.000000 | -36.980000 |
| 25% | 4097.000000 | 1.284350 |
| 50% | 8193.000000 | 4.227200 |
| 75% | 12289.000000 | 107.426300 |
| max | 16385.000000 | 59221.230000 |
df_indices.head()
| Unnamed: 0 | symbol | date | price | |
|---|---|---|---|---|
| 0 | 1 | DPROPANEMBTX | 2019-01-02 | 0.641 |
| 1 | 2 | DPROPANEMBTX | 2019-01-03 | 0.630 |
| 2 | 3 | DPROPANEMBTX | 2019-01-04 | 0.635 |
| 3 | 4 | DPROPANEMBTX | 2019-01-07 | 0.623 |
| 4 | 5 | DPROPANEMBTX | 2019-01-08 | 0.628 |
df_indices = df_indices[["symbol","date","price"]]
df_indices.tail()
| symbol | date | price | |
|---|---|---|---|
| 16380 | THREEFY5 | 2021-03-24 | 0.8123 |
| 16381 | THREEFY5 | 2021-03-25 | 0.8126 |
| 16382 | THREEFY5 | 2021-03-26 | 0.8354 |
| 16383 | THREEFY5 | 2021-03-29 | 0.8687 |
| 16384 | THREEFY5 | 2021-03-30 | 0.8818 |
df_SP500.head()
| symbol | company | identifier | sedol | weight | sector | shares_held | local_currency | exchange | |
|---|---|---|---|---|---|---|---|---|---|
| 1 | AAPL | Apple Inc. | 03783310 | 2046251 | 0.059338 | Information Technology | 161340980 | USD | SP500 |
| 2 | MSFT | Microsoft Corporation | 59491810 | 2588173 | 0.055094 | Information Technology | 77110660 | USD | SP500 |
| 3 | AMZN | Amazon.com Inc. | 02313510 | 2000019 | 0.040733 | Consumer Discretionary | 4376067 | USD | SP500 |
| 4 | FB | Facebook Inc. Class A | 30303M10 | B7TL820 | 0.021718 | Communication Services | 24592958 | USD | SP500 |
| 5 | GOOGL | Alphabet Inc. Class A | 02079K30 | BYVY8G0 | 0.019521 | Communication Services | 3074670 | USD | SP500 |
df = pd.concat([df_prices_adj,df_indices])
df['date'] = pd.to_datetime(df['date'], format='%Y%m%d', errors='ignore')
df.set_index(['date','symbol'],inplace=True)
df=df.unstack()['price']
df.fillna(method='bfill',inplace=True)
df
| symbol | A | AAL | AAP | AAPL | ABBV | ABC | ABMD | ABT | ACN | ADBE | ... | XEL | XLNX | XOM | XRAY | XYL | YUM | ZBH | ZBRA | ZION | ZTS |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| date | |||||||||||||||||||||
| 2019-01-02 | 64.511734 | 31.96316 | 156.2589 | 38.505024 | 79.101799 | 71.46416 | 309.96 | 67.034943 | 136.179626 | 224.570007 | ... | 45.400452 | 84.360565 | 60.557911 | 37.21114 | 64.63606 | 87.819199 | 100.576180 | 156.24 | 38.71991 | 83.337715 |
| 2019-01-03 | 62.135132 | 29.58167 | 161.1371 | 34.669640 | 76.495514 | 70.42746 | 302.29 | 63.871284 | 131.530212 | 215.699997 | ... | 45.221561 | 81.184296 | 59.628124 | 37.23077 | 62.42029 | 85.610275 | 98.756989 | 146.88 | 38.50573 | 80.457184 |
| 2019-01-04 | 64.285828 | 31.53016 | 157.1396 | 36.149662 | 78.959961 | 71.24338 | 313.44 | 65.694260 | 136.644577 | 226.190002 | ... | 45.664082 | 84.943359 | 61.826595 | 38.31106 | 65.05392 | 87.838394 | 102.129860 | 152.97 | 39.68837 | 83.613907 |
| 2019-01-07 | 65.650917 | 32.42568 | 159.4450 | 36.069202 | 80.112411 | 71.75211 | 314.80 | 66.678070 | 137.119217 | 229.259995 | ... | 45.466366 | 87.187141 | 62.148109 | 38.99852 | 64.09184 | 87.742371 | 102.169182 | 155.29 | 39.84668 | 84.117012 |
| 2019-01-08 | 66.613335 | 31.90411 | 158.3368 | 36.756794 | 80.484734 | 72.52003 | 318.42 | 65.877518 | 140.586914 | 232.679993 | ... | 45.993618 | 85.526176 | 62.599968 | 38.73336 | 64.69435 | 87.569496 | 99.877983 | 156.33 | 40.20985 | 85.369850 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2021-03-24 | 120.656403 | 21.81000 | 181.7300 | 120.089996 | 103.059998 | 115.37000 | 294.21 | 118.019997 | 267.549988 | 451.510010 | ... | 65.580002 | 119.959999 | 56.340000 | 60.25000 | 101.11000 | 107.080002 | 157.210648 | 463.81 | 53.01000 | 155.429993 |
| 2021-03-25 | 121.714798 | 22.77000 | 185.6500 | 120.589996 | 103.879997 | 117.34000 | 294.14 | 119.050003 | 268.609985 | 450.989990 | ... | 66.000000 | 120.029999 | 56.180000 | 60.55000 | 101.93000 | 107.379997 | 157.639999 | 461.26 | 54.74000 | 152.880005 |
| 2021-03-26 | 125.449112 | 22.93000 | 187.3200 | 121.209999 | 105.980003 | 118.73000 | 301.40 | 122.070000 | 280.769989 | 469.089996 | ... | 66.309998 | 123.139999 | 57.709999 | 61.28000 | 104.76000 | 108.059998 | 161.320007 | 476.96 | 55.85000 | 156.149994 |
| 2021-03-29 | 125.229446 | 22.91000 | 185.0600 | 121.389999 | 106.730003 | 119.05000 | 305.77 | 122.230003 | 279.540009 | 469.320007 | ... | 67.000000 | 122.230003 | 57.400002 | 62.06000 | 104.27000 | 109.209999 | 160.210007 | 467.07 | 53.89000 | 158.389999 |
| 2021-03-30 | 124.650322 | 24.12000 | 186.0700 | 119.900002 | 106.790001 | 119.06000 | 309.88 | 119.750000 | 278.549988 | 465.459991 | ... | 66.010002 | 120.300003 | 56.689999 | 63.54000 | 104.88000 | 109.769997 | 161.220001 | 474.83 | 55.91000 | 157.039993 |
565 rows × 531 columns
df = (df-df.mean())/df.std()
df.describe()
| symbol | A | AAL | AAP | AAPL | ABBV | ABC | ABMD | ABT | ACN | ADBE | ... | XEL | XLNX | XOM | XRAY | XYL | YUM | ZBH | ZBRA | ZION | ZTS |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 5.650000e+02 | 5.650000e+02 | 5.650000e+02 | 5.650000e+02 | 5.650000e+02 | 5.650000e+02 | 5.650000e+02 | 5.650000e+02 | 5.650000e+02 | 5.650000e+02 | ... | 5.650000e+02 | 5.650000e+02 | 5.650000e+02 | 5.650000e+02 | 5.650000e+02 | 5.650000e+02 | 5.650000e+02 | 5.650000e+02 | 5.650000e+02 | 5.650000e+02 |
| mean | -5.533430e-16 | -1.156990e-15 | -2.339132e-15 | 2.364284e-15 | -3.420666e-15 | -1.307902e-15 | 7.797106e-16 | 4.426744e-15 | 8.551665e-16 | 4.326136e-15 | ... | -1.237476e-14 | 4.099769e-15 | 7.545587e-16 | -1.760637e-16 | -7.646194e-15 | -1.936701e-15 | -2.678683e-15 | -1.810941e-15 | -2.867323e-15 | -3.068539e-15 |
| std | 1.000000e+00 | 1.000000e+00 | 1.000000e+00 | 1.000000e+00 | 1.000000e+00 | 1.000000e+00 | 1.000000e+00 | 1.000000e+00 | 1.000000e+00 | 1.000000e+00 | ... | 1.000000e+00 | 1.000000e+00 | 1.000000e+00 | 1.000000e+00 | 1.000000e+00 | 1.000000e+00 | 1.000000e+00 | 1.000000e+00 | 1.000000e+00 | 1.000000e+00 |
| min | -1.402956e+00 | -1.578205e+00 | -4.368070e+00 | -1.422373e+00 | -1.783790e+00 | -1.920594e+00 | -1.960001e+00 | -1.883874e+00 | -2.071674e+00 | -1.646058e+00 | ... | -2.597860e+00 | -2.077320e+00 | -1.906102e+00 | -2.730556e+00 | -2.111907e+00 | -4.089893e+00 | -3.106090e+00 | -1.373928e+00 | -2.269724e+00 | -2.059833e+00 |
| 25% | -7.205020e-01 | -1.081580e+00 | -3.269484e-01 | -9.160365e-01 | -8.075055e-01 | -6.871508e-01 | -9.956515e-01 | -7.258871e-01 | -7.138452e-01 | -9.190687e-01 | ... | -5.309481e-01 | -7.727544e-01 | -9.708038e-01 | -8.461749e-01 | -5.681917e-01 | -6.355256e-01 | -7.359661e-01 | -6.979548e-01 | -1.004871e+00 | -7.099711e-01 |
| 50% | -3.988059e-01 | 3.186508e-01 | 2.191719e-01 | -2.702986e-01 | -7.196453e-02 | -2.771314e-01 | 2.134506e-01 | -3.168558e-01 | -2.189815e-01 | -2.961142e-01 | ... | 6.798383e-02 | -1.999376e-01 | 3.236947e-01 | 1.573233e-01 | -1.819963e-01 | 3.273311e-02 | 1.208611e-01 | -2.155373e-01 | 2.149392e-01 | -1.179682e-01 |
| 75% | 6.010351e-01 | 8.994444e-01 | 5.329562e-01 | 1.102648e+00 | 7.246279e-01 | 7.769495e-01 | 8.128134e-01 | 8.944433e-01 | 7.914156e-01 | 1.047349e+00 | ... | 6.942542e-01 | 6.930862e-01 | 8.373723e-01 | 8.655397e-01 | 3.657484e-01 | 7.911210e-01 | 7.965623e-01 | 2.228456e-01 | 6.929752e-01 | 1.075490e+00 |
| max | 2.370841e+00 | 1.631285e+00 | 2.129579e+00 | 2.053239e+00 | 2.192993e+00 | 2.759439e+00 | 1.856881e+00 | 2.525851e+00 | 2.386994e+00 | 1.970695e+00 | ... | 2.121844e+00 | 2.439377e+00 | 1.533337e+00 | 2.122636e+00 | 2.542459e+00 | 1.801157e+00 | 1.843039e+00 | 3.113057e+00 | 2.442046e+00 | 1.818189e+00 |
8 rows × 531 columns
2. Data Visualization
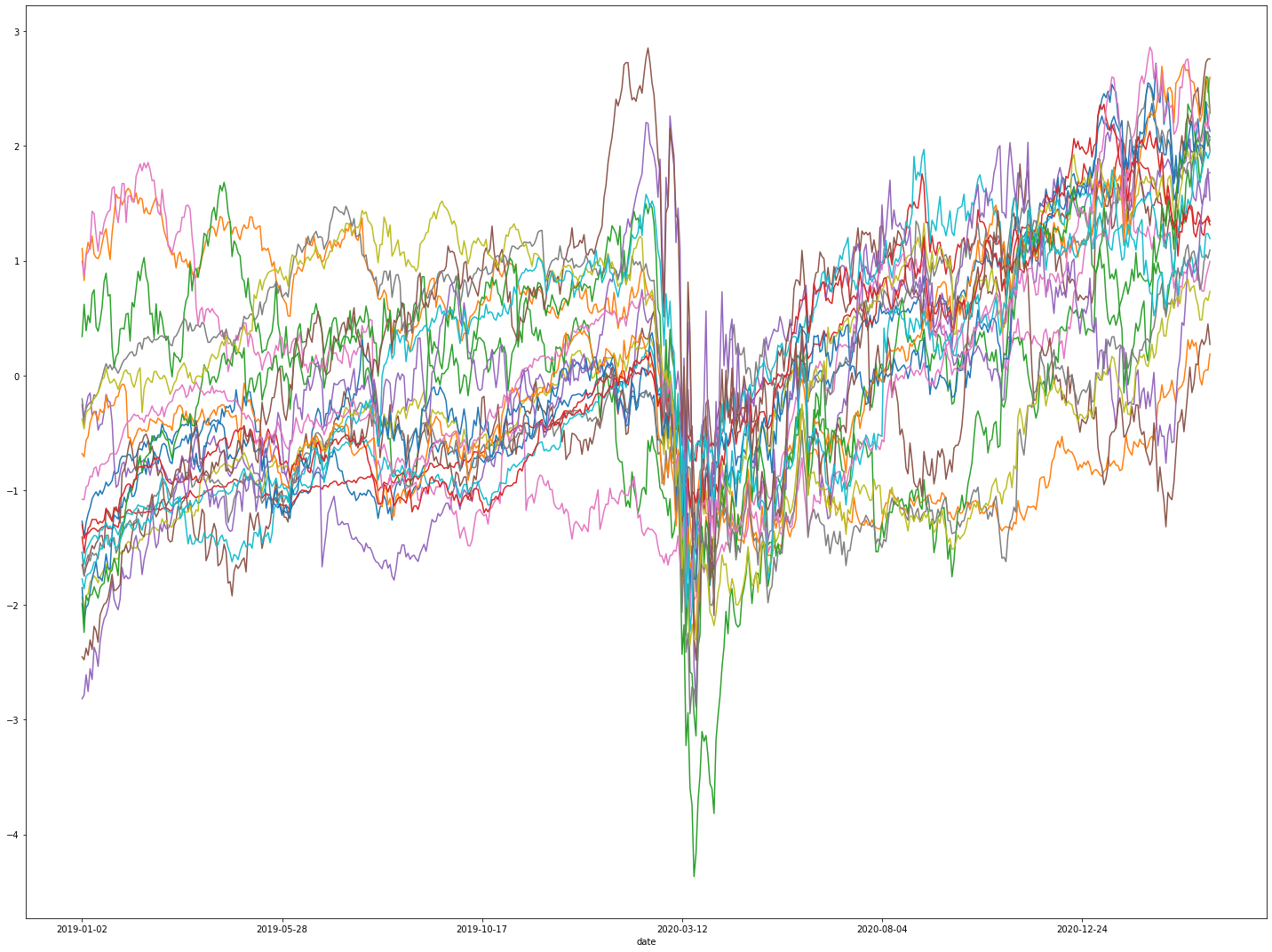
2.1. Stock Price Volatility
%matplotlib inline
fig, ax1 = plt.subplots(figsize=(20, 15))
df.iloc[:,:20].plot(ax=ax1, legend=False)
plt.tight_layout()
plt.show()
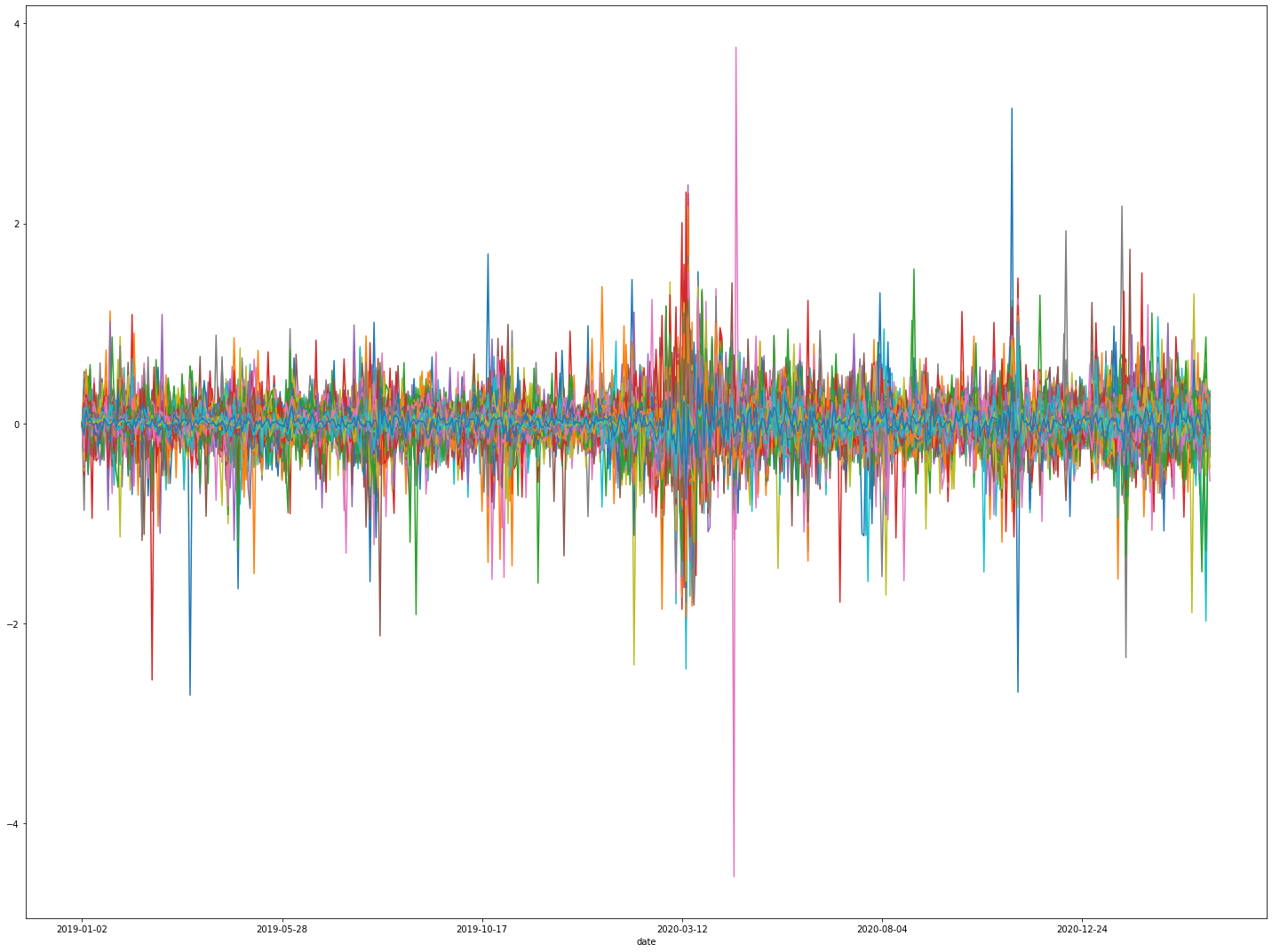
df_delta = df.copy()
for column in df_delta.columns.values.tolist():
df_delta[column] = df_delta[column]- df_delta[column].shift(1)
df_delta.iloc[0]=0
df_delta
| symbol | A | AAL | AAP | AAPL | ABBV | ABC | ABMD | ABT | ACN | ADBE | ... | XEL | XLNX | XOM | XRAY | XYL | YUM | ZBH | ZBRA | ZION | ZTS |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| date | |||||||||||||||||||||
| 2019-01-02 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | ... | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 2019-01-03 | -0.132308 | -0.278940 | 0.281110 | -0.123113 | -0.190242 | -0.096013 | -0.126329 | -0.210193 | -0.138905 | -0.100851 | ... | -0.029680 | -0.171040 | -0.072336 | 0.002954 | -0.197347 | -0.215205 | -0.106702 | -0.114809 | -0.028157 | -0.119316 |
| 2019-01-04 | 0.119732 | 0.228224 | -0.230359 | 0.047508 | 0.179889 | 0.075565 | 0.183646 | 0.121119 | 0.152796 | 0.119270 | ... | 0.073418 | 0.202423 | 0.171038 | 0.162583 | 0.234564 | 0.217075 | 0.197830 | 0.074699 | 0.155477 | 0.130757 |
| 2019-01-07 | 0.075996 | 0.104891 | 0.132851 | -0.002583 | 0.084121 | 0.047115 | 0.022400 | 0.065364 | 0.014180 | 0.034905 | ... | -0.032803 | 0.120826 | 0.025013 | 0.103462 | -0.085687 | -0.009355 | 0.002306 | 0.028457 | 0.020812 | 0.020839 |
| 2019-01-08 | 0.053579 | -0.061091 | -0.063861 | 0.022071 | 0.027177 | 0.071120 | 0.059623 | -0.053189 | 0.103600 | 0.038885 | ... | 0.087476 | -0.089442 | 0.035154 | -0.039906 | 0.053662 | -0.016842 | -0.134387 | 0.012757 | 0.047745 | 0.051895 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2021-03-24 | -0.063369 | -0.053879 | 0.126777 | -0.078644 | -0.129928 | 0.148182 | -0.072635 | -0.164107 | 0.045411 | -0.098804 | ... | 0.023227 | -0.116853 | 0.087134 | 0.063104 | 0.063236 | -0.089631 | 0.076719 | 0.014228 | -0.074936 | -0.025267 |
| 2021-03-25 | 0.058922 | 0.112443 | 0.225893 | 0.016050 | 0.059855 | 0.182449 | -0.001153 | 0.068434 | 0.031668 | -0.005913 | ... | 0.069681 | 0.003769 | -0.012448 | 0.045150 | 0.073033 | 0.029227 | 0.025183 | -0.031278 | 0.227436 | -0.105625 |
| 2021-03-26 | 0.207894 | 0.018741 | 0.096235 | 0.019902 | 0.153287 | 0.128733 | 0.119576 | 0.200649 | 0.363291 | 0.205795 | ... | 0.051431 | 0.167471 | 0.119032 | 0.109865 | 0.252053 | 0.066249 | 0.215845 | 0.192574 | 0.145927 | 0.135448 |
| 2021-03-29 | -0.012229 | -0.002343 | -0.130234 | 0.005778 | 0.054745 | 0.029636 | 0.071976 | 0.010631 | -0.036747 | 0.002615 | ... | 0.114477 | -0.049003 | -0.024117 | 0.117390 | -0.043642 | 0.112039 | -0.065105 | -0.121310 | -0.257674 | 0.092785 |
| 2021-03-30 | -0.032241 | 0.141726 | 0.058202 | -0.047828 | 0.004379 | 0.000926 | 0.067694 | -0.164771 | -0.029578 | -0.043888 | ... | -0.164249 | -0.103929 | -0.055237 | 0.222739 | 0.054329 | 0.054558 | 0.059240 | 0.095183 | 0.265562 | -0.055920 |
565 rows × 531 columns
%matplotlib inline
fig, ax1 = plt.subplots(figsize=(20, 15))
df_delta.plot(ax=ax1, legend=False)
plt.tight_layout()
plt.show()
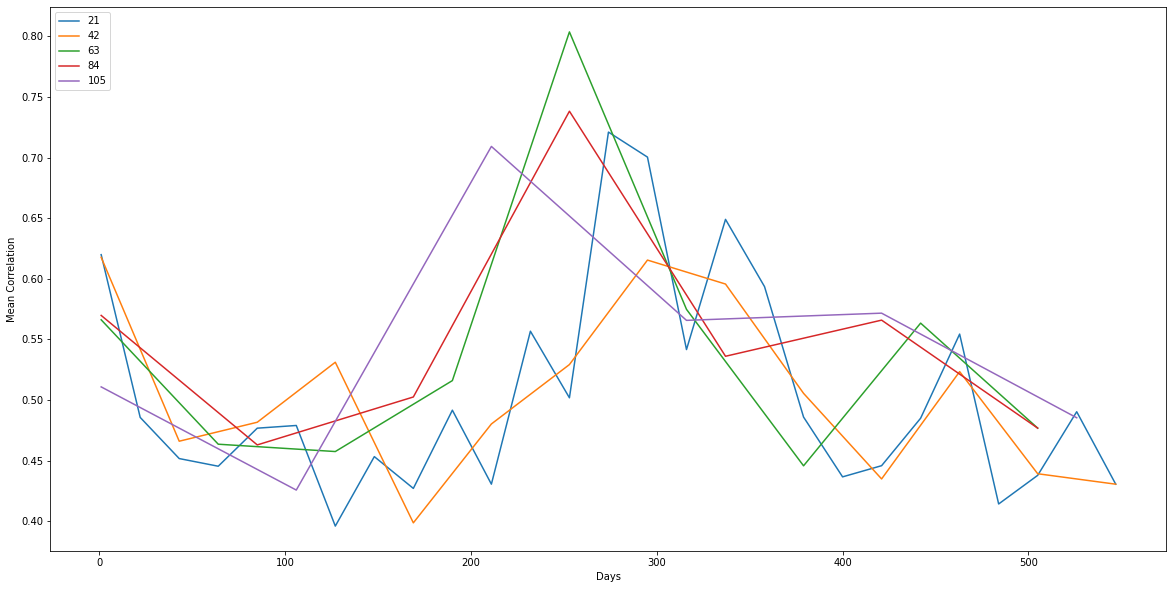
2.2. Rolling Average of Stock Price Correlation
def calculate_corr(df_stock_returns, returns_window, corr_window_size, corr_method):
stocks_cross_corr_dict = {}
x_days = []
y_mean_corr = []
for i in range(returns_window,len(df_stock_returns),corr_window_size):
dic_key = i
stocks_cross_corr_dict[dic_key]=df_stock_returns.iloc[i:(i+W)].corr(method='pearson')
stocks_cross_corr_dict[dic_key].fillna(0,inplace=True)
x_days.append(dic_key)
y_mean_corr.append(np.mean([abs(j) for j in stocks_cross_corr_dict[dic_key].values.flatten().tolist()]))
return stocks_cross_corr_dict, x_days,y_mean_corr
%matplotlib inline
start = 21
end = 126
step = 21;
plt.figure(figsize=(20, 10))
for t in range(start, end, step):
x_days = []
y_mean_corr = []
W = t
_, x_days, y_mean_corr = calculate_corr(df,1,W, 'pearson')
plt.plot(x_days, y_mean_corr)
plt.xlabel('Days')
plt.ylabel('Mean Correlation')
l = list(range(start, end, step))
plt.legend(l, loc='upper left')
plt.show()
3. Network Analysis
3.1. Build Graph with Correlation table
# craetes a graph from correlation matrix
cor_matrix = df.corr()
cor_matrix
| symbol | A | AAL | AAP | AAPL | ABBV | ABC | ABMD | ABT | ACN | ADBE | ... | XEL | XLNX | XOM | XRAY | XYL | YUM | ZBH | ZBRA | ZION | ZTS |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| symbol | |||||||||||||||||||||
| A | 1.000000 | -0.512211 | 0.340607 | 0.936847 | 0.901146 | 0.866659 | 0.476208 | 0.932064 | 0.916575 | 0.876950 | ... | 0.581891 | 0.661159 | -0.481706 | 0.276888 | 0.819616 | 0.232105 | 0.731162 | 0.947770 | 0.196208 | 0.830023 |
| AAL | -0.512211 | 1.000000 | 0.452672 | -0.709976 | -0.567905 | -0.636546 | 0.067317 | -0.620271 | -0.515571 | -0.761706 | ... | -0.685099 | 0.040970 | 0.950026 | 0.414638 | -0.104279 | 0.401344 | -0.116920 | -0.402034 | 0.675397 | -0.720983 |
| AAP | 0.340607 | 0.452672 | 1.000000 | 0.132583 | 0.218725 | 0.129889 | 0.598790 | 0.206132 | 0.304547 | 0.062110 | ... | -0.102458 | 0.592191 | 0.471304 | 0.536131 | 0.517752 | 0.604171 | 0.464449 | 0.358634 | 0.691259 | 0.045798 |
| AAPL | 0.936847 | -0.709976 | 0.132583 | 1.000000 | 0.883271 | 0.900174 | 0.311099 | 0.946722 | 0.931212 | 0.971310 | ... | 0.752885 | 0.464395 | -0.694573 | 0.138280 | 0.700491 | 0.103699 | 0.668931 | 0.859869 | -0.067884 | 0.937015 |
| ABBV | 0.901146 | -0.567905 | 0.218725 | 0.883271 | 1.000000 | 0.842135 | 0.379425 | 0.820668 | 0.826314 | 0.834858 | ... | 0.525801 | 0.430849 | -0.525965 | 0.167883 | 0.625416 | 0.017315 | 0.617159 | 0.868875 | 0.131018 | 0.756742 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| YUM | 0.232105 | 0.401344 | 0.604171 | 0.103699 | 0.017315 | 0.148166 | 0.135065 | 0.246568 | 0.391225 | 0.042001 | ... | 0.150926 | 0.517301 | 0.446745 | 0.791644 | 0.591224 | 1.000000 | 0.622313 | 0.311883 | 0.601129 | 0.211623 |
| ZBH | 0.731162 | -0.116920 | 0.464449 | 0.668931 | 0.617159 | 0.647128 | 0.138407 | 0.709774 | 0.815626 | 0.581120 | ... | 0.583386 | 0.473123 | -0.072924 | 0.677935 | 0.793259 | 0.622313 | 1.000000 | 0.754226 | 0.495103 | 0.715109 |
| ZBRA | 0.947770 | -0.402034 | 0.358634 | 0.859869 | 0.868875 | 0.842147 | 0.398625 | 0.902315 | 0.895845 | 0.774380 | ... | 0.477856 | 0.635769 | -0.332037 | 0.410140 | 0.824975 | 0.311883 | 0.754226 | 1.000000 | 0.353050 | 0.754373 |
| ZION | 0.196208 | 0.675397 | 0.691259 | -0.067884 | 0.131018 | 0.003435 | 0.274263 | 0.036986 | 0.155021 | -0.207014 | ... | -0.314988 | 0.431878 | 0.711608 | 0.768845 | 0.486766 | 0.601129 | 0.495103 | 0.353050 | 1.000000 | -0.148741 |
| ZTS | 0.830023 | -0.720983 | 0.045798 | 0.937015 | 0.756742 | 0.869275 | 0.075617 | 0.902965 | 0.917018 | 0.930572 | ... | 0.901222 | 0.331572 | -0.696158 | 0.206471 | 0.652798 | 0.211623 | 0.715109 | 0.754373 | -0.148741 | 1.000000 |
531 rows × 531 columns
mat_pos = cor_matrix[cor_matrix>=0]
mat_pos = mat_pos.fillna(0)
symbols = cor_matrix.index.values
mat_pos = np.asmatrix(mat_pos)
G_pos = nx.from_numpy_matrix(mat_pos)
G_pos = nx.relabel_nodes(G_pos,lambda x: symbols[x])
G_pos.remove_edges_from(nx.selfloop_edges(G_pos))
mat_neg = cor_matrix[cor_matrix<0]
mat_neg = mat_neg.fillna(0)
mat_neg = abs(mat_neg)
symbols = cor_matrix.index.values
mat_neg = np.asmatrix(mat_neg)
G_neg = nx.from_numpy_matrix(mat_neg)
G_neg = nx.relabel_nodes(G_neg,lambda x: symbols[x])
G_neg.remove_edges_from(nx.selfloop_edges(G_neg))
list(G_pos.edges(data=True))[:5], list(G_neg.edges(data=True))[:5]
([('A', 'AAP', {'weight': 0.3406072572702165}),
('A', 'AAPL', {'weight': 0.9368465656977406}),
('A', 'ABBV', {'weight': 0.9011464914155253}),
('A', 'ABC', {'weight': 0.8666593549791352}),
('A', 'ABMD', {'weight': 0.476208419378593})],
[('A', 'AAL', {'weight': 0.5122106576033231}),
('A', 'AEP', {'weight': 0.010066159905771194}),
('A', 'AFL', {'weight': 0.14527226301899576}),
('A', 'AIG', {'weight': 0.21700976911380374}),
('A', 'ALK', {'weight': 0.13546044591421322})])
symbol = df.columns
df_sector = df_SP500[df_SP500['symbol'].isin(symbol)]
df_sector = df_sector[["symbol","sector"]]
tmp = pd.DataFrame({"symbol":df_indices["symbol"].unique(), "sector":"Macroeconomic Indices"})
df_sector = pd.concat([df_sector,tmp],ignore_index=True)
df_sector['sec_idx']= 0
for i,sec in enumerate(df_sector["sector"].unique()):
df_sector.loc[df_sector['sector']==sec,'sec_idx'] = i+1
df_sector
| symbol | sector | sec_idx | |
|---|---|---|---|
| 0 | AAPL | Information Technology | 1 |
| 1 | MSFT | Information Technology | 1 |
| 2 | AMZN | Consumer Discretionary | 2 |
| 3 | FB | Communication Services | 3 |
| 4 | GOOGL | Communication Services | 3 |
| ... | ... | ... | ... |
| 526 | GOLDAMGBD228NLBM | Macroeconomic Indices | 12 |
| 527 | IOER | Macroeconomic Indices | 12 |
| 528 | IORR | Macroeconomic Indices | 12 |
| 529 | THREEFY1 | Macroeconomic Indices | 12 |
| 530 | THREEFY5 | Macroeconomic Indices | 12 |
531 rows × 3 columns
nx.set_node_attributes(G_pos, df_sector.set_index('symbol')['sec_idx'],'sec_idx')
nx.set_node_attributes(G_neg, df_sector.set_index('symbol')['sec_idx'],'sec_idx')
3.2. Setting threshold on weights
def set_threshold(G,threshold):
edges_rm = list(filter(lambda e: abs(e[2]) < threshold, (e for e in G.edges.data('weight'))))
ids_rm = list(e[:2] for e in edges_rm)
H = G.copy()
H.remove_edges_from(ids_rm)
return H
H_pos = set_threshold(G_pos,0.5)
H_neg = set_threshold(G_neg,0.5)
list(H_pos.edges(data=True))[:5], list(H_neg.edges(data=True))[:5]
([('A', 'AAPL', {'weight': 0.9368465656977406}),
('A', 'ABBV', {'weight': 0.9011464914155253}),
('A', 'ABC', {'weight': 0.8666593549791352}),
('A', 'ABT', {'weight': 0.932064482315709}),
('A', 'ACN', {'weight': 0.916574717968791})],
[('A', 'AAL', {'weight': 0.5122106576033231}),
('A', 'BA', {'weight': 0.5064885797862092}),
('A', 'BXP', {'weight': 0.522527131570438}),
('A', 'CCL', {'weight': 0.5559250497113872}),
('A', 'DEXCAUS', {'weight': 0.6382900166453468})])
3.3. Community Detection
- with Louvain Algorithm
# grid search
# for positive weights
np.random.seed(2021)
t=0
for cor_thresold in np.linspace(0.8,0.85,20):
H_pos = set_threshold(G_pos,cor_thresold)
partition = louvain.best_partition(H_pos)
modularity = louvain.modularity(partition, H_pos)
values = [partition.get(node) for node in H_pos.nodes()]
communities = []
tmp = list(partition.items())
for i in range(len(set(values))):
communities.append([n for n,c in tmp if c==i])
sum_comm_nodes = 0
k=0
print("{}th Total number of Communities = {}".format(t ,len(communities)))
for i, comm_nodes in enumerate(communities):
if len(comm_nodes)>=10:
k+=1
print('community {}th: '.format(i),len(comm_nodes))
sum_comm_nodes+=len(comm_nodes)
t+=1
print('n_big_communities: ',k)
# best partition with 5 big communities at cor_threshold = np.linspace(0.8,0.85,20)[8]
...
5th Total number of Communities = 36
community 0th: 162
community 1th: 188
community 4th: 103
community 6th: 35
n_big_communities: 4
6th Total number of Communities = 36
community 0th: 172
community 1th: 180
community 3th: 113
community 4th: 25
n_big_communities: 4
7th Total number of Communities = 36
community 0th: 152
community 3th: 112
community 4th: 46
community 6th: 180
n_big_communities: 4
8th Total number of Communities = 41
community 2th: 77
community 4th: 107
community 5th: 157
community 7th: 37
community 9th: 108
n_big_communities: 5
9th Total number of Communities = 41
community 0th: 153
community 4th: 103
community 6th: 43
community 7th: 79
community 9th: 108
n_big_communities: 5
10th Total number of Communities = 41
community 0th: 146
community 2th: 84
community 4th: 109
community 6th: 41
community 9th: 106
n_big_communities: 5
11th Total number of Communities = 42
community 0th: 145
community 2th: 178
community 4th: 126
community 8th: 35
n_big_communities: 4
...
np.random.seed(2021)
cor_thresold = np.linspace(0.8,0.85,20)[8]
H_pos = set_threshold(G_pos,cor_thresold)
partition = louvain.best_partition(H_pos)
values = [partition.get(node) for node in H_pos.nodes()]
communities = []
tmp = list(partition.items())
for i in range(len(set(values))):
communities.append([n for n,c in tmp if c==i])
sum_comm_nodes = 0
k=0
print("Total number of Communities = {}".format(len(communities)))
for i, comm_nodes in enumerate(communities):
if len(comm_nodes)>=10:
k+=1
print('community {}th: '.format(i),len(comm_nodes))
sum_comm_nodes+=len(comm_nodes)
print('n_big_communities: ',k)
Total number of Communities = 41
community 0th: 164
community 2th: 79
community 4th: 105
community 7th: 30
community 9th: 108
n_big_communities: 5
nx.set_node_attributes(H_pos,partition,'community')
values = [partition.get(node) for node in H_pos.nodes()]
plt.figure(figsize=(10,10))
nx.draw_spring(H_pos, cmap = plt.get_cmap('jet'), node_color = values, node_size=30, with_labels=False)
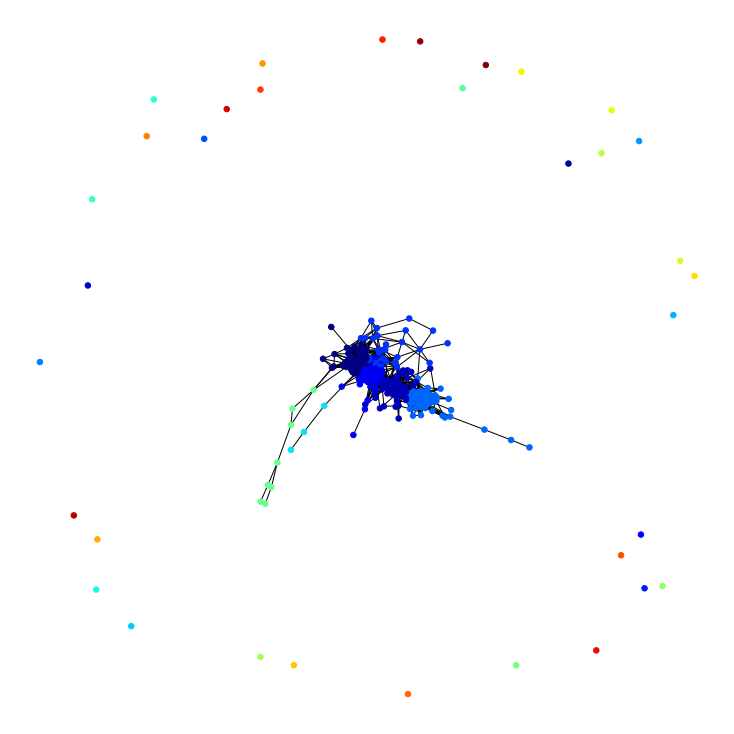
np.random.seed(2021)
# for negative weights
t=0
for cor_thresold in np.linspace(0.6,0.65,20):
H_neg = set_threshold(G_neg,cor_thresold)
partition = louvain.best_partition(H_neg)
modularity = louvain.modularity(partition, H_neg)
values = [partition.get(node) for node in H_neg.nodes()]
communities = []
tmp = list(partition.items())
for i in range(len(set(values))):
communities.append([n for n,c in tmp if c==i])
sum_comm_nodes = 0
k=0
print("{}th Total number of Communities = {}".format(t ,len(communities)))
for i, comm_nodes in enumerate(communities):
if len(comm_nodes)>=10:
k+=1
print('community {}th: '.format(i),len(comm_nodes))
sum_comm_nodes+=len(comm_nodes)
t+=1
print('n_big_communities: ',k)
# best partition with 5 big communities at cor_threshold = np.linspace(0.6,0.65,20)[11]
...
9th Total number of Communities = 37
community 0th: 104
community 1th: 83
community 2th: 177
community 5th: 119
community 6th: 16
n_big_communities: 5
10th Total number of Communities = 40
community 0th: 103
community 1th: 83
community 2th: 177
community 3th: 14
community 6th: 119
n_big_communities: 5
11th Total number of Communities = 41
community 0th: 104
community 1th: 83
community 2th: 176
community 3th: 13
community 6th: 119
n_big_communities: 5
12th Total number of Communities = 42
community 0th: 103
community 1th: 81
community 3th: 13
community 6th: 130
community 11th: 167
n_big_communities: 5
13th Total number of Communities = 42
community 0th: 106
community 1th: 81
community 2th: 176
community 6th: 118
community 7th: 13
n_big_communities: 5
14th Total number of Communities = 43
community 0th: 204
community 1th: 165
community 2th: 18
community 5th: 105
n_big_communities: 4
...
np.random.seed(2021)
cor_thresold = np.linspace(0.6,0.65,20)[11]
H_neg_otim = set_threshold(G_neg,cor_thresold)
partition = louvain.best_partition(H_neg_otim)
modularity = louvain.modularity(partition, H_neg)
values = [partition.get(node) for node in H_neg.nodes()]
communities = []
tmp = list(partition.items())
for i in range(len(set(values))):
communities.append([n for n,c in tmp if c==i])
sum_comm_nodes = 0
k=0
print("Total number of Communities = {}".format(len(communities)))
for i, comm_nodes in enumerate(communities):
if len(comm_nodes)>=10:
k+=1
print('community {}th: '.format(i),len(comm_nodes))
sum_comm_nodes+=len(comm_nodes)
print('n_big_communities: ',k)
Total number of Communities = 41
community 0th: 102
community 1th: 83
community 3th: 13
community 6th: 130
community 11th: 167
n_big_communities: 5
nx.set_node_attributes(H_neg, partition,'community')
values = [partition.get(node) for node in H_neg.nodes()]
plt.figure(figsize=(10,10))
nx.draw_spring(H_neg, cmap = plt.get_cmap('jet'), node_color = values, node_size=30, with_labels=False)

3.4. Visualization with Gephi
nx.write_graphml(H_pos, "model_H_pos.graphml")
nx.write_graphml(H_neg, "model_H_neg.graphml")
