R - Air Pollution Data Analysis
1. About
- 2020-2, Data Science and R, Final Proejct: Air Pollution Data Analysis
2. Load Data and Preprocess
- Collected data from Air Korea (https://www.airkorea.or.kr)
library(dplyr)
library(tidyverse)
library(grid)
library(vcd)
library(ggplot2)
library(readxl)
data= read_xlsx("./final_data/data.xlsx");
head(data,5)
nrow(data)
| 날짜 | 시도 | 측정소명 | 측정소코드 | 아황산가스 | 일산화탄소 | 오존 | 이산화질소 | PM10 | PM2.5 |
|---|---|---|---|---|---|---|---|---|---|
| 2017-07-01 01 | 인천 옹진군 | 백령도 | 831492 | .0016 | .3 | .052 | .0016 | 44 | 35 |
| 2017-07-01 02 | 인천 옹진군 | 백령도 | 831492 | .0016 | .3 | .052 | .0017 | 21 | NA |
| 2017-07-01 03 | 인천 옹진군 | 백령도 | 831492 | .0017 | .3 | .051 | .0017 | 32 | 18 |
| 2017-07-01 04 | 인천 옹진군 | 백령도 | 831492 | .0017 | .3 | .05 | .002 | 10 | NA |
| 2017-07-01 05 | 인천 옹진군 | 백령도 | 831492 | .0016 | .3 | .048 | .0018 | 24 | 22 |
26304
2.1. Set Attributes
# 시도, 측정소명, 측정소코드는 모두 같으므로 제외
# 날짜는 시구간별 분석을 위해 연, 월, 일, 시로 분리: int타입으로 반환됨
# 측정 대상 오염 물질의 자료형 변환
data <- data %>%
select(-c(시도,측정소명,측정소코드)) %>%
separate(col=날짜,
into=c("year","month","day","hour"),
convert=TRUE) %>%
mutate_if(is.character,as.numeric) %>%
rename(SO2=아황산가스,CO=일산화탄소,O3=오존,NO2=이산화질소)
head(data,5)
| year | month | day | hour | SO2 | CO | O3 | NO2 | PM10 | PM2.5 |
|---|---|---|---|---|---|---|---|---|---|
| 2017 | 7 | 1 | 1 | 0.0016 | 0.3 | 0.052 | 0.0016 | 44 | 35 |
| 2017 | 7 | 1 | 2 | 0.0016 | 0.3 | 0.052 | 0.0017 | 21 | NA |
| 2017 | 7 | 1 | 3 | 0.0017 | 0.3 | 0.051 | 0.0017 | 32 | 18 |
| 2017 | 7 | 1 | 4 | 0.0017 | 0.3 | 0.050 | 0.0020 | 10 | NA |
| 2017 | 7 | 1 | 5 | 0.0016 | 0.3 | 0.048 | 0.0018 | 24 | 22 |
2.2. Handling NA values
# 일평균 값을 확인
daily <- data %>%
group_by(year,month,day) %>%
select_if(is.double) %>%
summarise_all(mean,na.rm=TRUE) %>%
ungroup()
summary(daily)
year month day SO2
Min. :2017 Min. : 1.000 Min. : 1.00 Min. :0.0001765
1st Qu.:2018 1st Qu.: 4.000 1st Qu.: 8.00 1st Qu.:0.0012553
Median :2018 Median : 7.000 Median :16.00 Median :0.0017042
Mean :2018 Mean : 6.522 Mean :15.73 Mean :0.0018339
3rd Qu.:2019 3rd Qu.:10.000 3rd Qu.:23.00 3rd Qu.:0.0022417
Max. :2020 Max. :12.000 Max. :31.00 Max. :0.0078375
NA's :1
CO O3 NO2 PM10
Min. :0.04583 Min. :0.01188 Min. :0.000850 Min. : 2.00
1st Qu.:0.23750 1st Qu.:0.03453 1st Qu.:0.002373 1st Qu.: 20.88
Median :0.32917 Median :0.04290 Median :0.003296 Median : 29.25
Mean :0.37287 Mean :0.04405 Mean :0.003853 Mean : 35.58
3rd Qu.:0.46667 3rd Qu.:0.05192 3rd Qu.:0.004764 3rd Qu.: 42.54
Max. :1.39167 Max. :0.09971 Max. :0.020209 Max. :217.04
NA's :2 NA's :5
PM2.5
Min. : 1.826
1st Qu.: 10.042
Median : 14.625
Mean : 18.736
3rd Qu.: 22.375
Max. :126.375
NA's :23
# NA: 하루 전체 관측치가 NA인 경우에 발생
# 월평균 값을 확인
monthly <- data %>%
group_by(year,month) %>%
select_if(is.double) %>%
summarise_all(mean,na.rm=TRUE) %>%
ungroup()
summary(monthly)
year month SO2 CO
Min. :2017 Min. : 1.00 Min. :0.001099 Min. :0.1911
1st Qu.:2018 1st Qu.: 3.75 1st Qu.:0.001394 1st Qu.:0.2646
Median :2018 Median : 6.50 Median :0.001789 Median :0.3562
Mean :2018 Mean : 6.50 Mean :0.001832 Mean :0.3730
3rd Qu.:2019 3rd Qu.: 9.25 3rd Qu.:0.002084 3rd Qu.:0.4491
Max. :2020 Max. :12.00 Max. :0.003140 Max. :0.7588
O3 NO2 PM10 PM2.5
Min. :0.02447 Min. :0.001857 Min. :20.24 Min. :10.62
1st Qu.:0.03821 1st Qu.:0.002876 1st Qu.:27.31 1st Qu.:13.94
Median :0.04175 Median :0.004066 Median :35.42 Median :18.41
Mean :0.04410 Mean :0.003850 Mean :35.69 Mean :18.92
3rd Qu.:0.05154 3rd Qu.:0.004658 3rd Qu.:42.46 3rd Qu.:22.84
Max. :0.06422 Max. :0.005683 Max. :58.00 Max. :36.51
# NA값들을 일평균 또는 월평균 값으로 대체
for (i in (1:nrow(data))){
for (j in c("SO2","CO","O3","NO2","PM10","PM2.5")){
if (is.na(data[i,][[j]])){
tmp<-data[i,]
y<-tmp$year
m<-tmp$month
d<-tmp$day
if (!is.nan(daily[daily$year==y & daily$month==m & daily$day==d,][[j]])){
data[i,][[j]]<-daily[daily$year==y & daily$month==m & daily$day==d,][[j]]
}else{
data[i,][[j]]<-monthly[monthly$year==y & monthly$month==m,][[j]]
}
}
}
}
summary(data)
year month day hour
Min. :2017 Min. : 1.000 Min. : 1.00 Min. : 1.00
1st Qu.:2018 1st Qu.: 4.000 1st Qu.: 8.00 1st Qu.: 6.75
Median :2018 Median : 7.000 Median :16.00 Median :12.50
Mean :2018 Mean : 6.522 Mean :15.73 Mean :12.50
3rd Qu.:2019 3rd Qu.:10.000 3rd Qu.:23.00 3rd Qu.:18.25
Max. :2020 Max. :12.000 Max. :31.00 Max. :24.00
SO2 CO O3 NO2
Min. :0.000000 Min. :0.0000 Min. :0.00100 Min. :0.000300
1st Qu.:0.001200 1st Qu.:0.2000 1st Qu.:0.03400 1st Qu.:0.002100
Median :0.001700 Median :0.3000 Median :0.04300 Median :0.003000
Mean :0.001834 Mean :0.3726 Mean :0.04405 Mean :0.003853
3rd Qu.:0.002300 3rd Qu.:0.5000 3rd Qu.:0.05200 3rd Qu.:0.004600
Max. :0.034700 Max. :2.5000 Max. :0.13200 Max. :0.045900
PM10 PM2.5
Min. : 1.00 Min. : 0.00
1st Qu.: 19.00 1st Qu.: 9.00
Median : 28.00 Median : 14.00
Mean : 35.57 Mean : 18.78
3rd Qu.: 43.00 3rd Qu.: 22.77
Max. :461.00 Max. :219.00
3. EDA
3.1. 통합대기환경지수(Comprehensive air-quality index), CAI 계산
### 통합대기환경지수CAI 지수를 계산
# 항목별 계산 함수를 정의
SO2_I_p <- function(C_p){
cut <- c(-Inf,0,0.02,0.05,0.15,1,Inf)
BP_hi <- as.numeric(as.character(cut(C_p, breaks=cut,right=TRUE,
include.lowest = FALSE, labels=c(0.02,0.02,0.05,0.15,1,1))))
BP_lo <- as.numeric(as.character(cut(C_p, breaks=cut,right=TRUE,
include.lowest = FALSE, labels=c(0,0,0.021,0.051,0.151,0.151))))
I_hi <- as.numeric(as.character(cut(C_p, breaks=cut,right=TRUE,
include.lowest = FALSE, labels=c(50,50,100,250,500,500))))
I_lo <- as.numeric(as.character(cut(C_p, breaks=cut,right=TRUE,
include.lowest = FALSE, labels=c(0,0,51,101,251,251))))
I_p <- (((I_hi-I_lo)/(BP_hi-BP_lo)) * (C_p - BP_lo)) + I_lo
return(I_p)
}
CO_I_p <- function(C_p){
cut <- c(-Inf,0,2,9,15,50,Inf)
BP_hi <- as.numeric(as.character(cut(C_p, breaks=cut,right=TRUE,
include.lowest = FALSE, labels=c(2,2,9,15,50,50))))
BP_lo <- as.numeric(as.character(cut(C_p, breaks=cut,right=TRUE,
include.lowest = FALSE, labels=c(0,0,2.01,9.01,15.01,15.01))))
I_hi <- as.numeric(as.character(cut(C_p, breaks=cut,right=TRUE,
include.lowest = FALSE, labels=c(50,50,100,250,500,500))))
I_lo <- as.numeric(as.character(cut(C_p, breaks=cut,right=TRUE,
include.lowest = FALSE, labels=c(0,0,51,101,251,251))))
I_p <- (I_hi-I_lo)/(BP_hi-BP_lo) * (C_p - BP_lo) + I_lo
return(I_p)
}
O3_I_p <- function(C_p){
cut <- c(-Inf,0,0.03,0.09,0.15,0.6,Inf)
BP_hi <- as.numeric(as.character(cut(C_p, breaks=cut,right=TRUE,
include.lowest = FALSE, labels=c(0.03,0.03,0.09,0.15,0.6,0.6))))
BP_lo <- as.numeric(as.character(cut(C_p, breaks=cut,right=TRUE,
include.lowest = FALSE, labels=c(0,0,0.031,0.091,0.151,0.151))))
I_hi <- as.numeric(as.character(cut(C_p, breaks=cut,right=TRUE,
include.lowest = FALSE, labels=c(50,50,100,250,500,500))))
I_lo <- as.numeric(as.character(cut(C_p, breaks=cut,right=TRUE,
include.lowest = FALSE, labels=c(0,0,51,101,251,251))))
I_p <- (I_hi-I_lo)/(BP_hi-BP_lo) * (C_p - BP_lo) + I_lo
return(I_p)
}
NO2_I_p <- function(C_p){
cut <- c(-Inf,0,0.03,0.06,0.2,2,Inf)
BP_hi <- as.numeric(as.character(cut(C_p, breaks=cut,right=TRUE,
include.lowest = FALSE, labels=c(0.03,0.03,0.06,0.2,2,2))))
BP_lo <- as.numeric(as.character(cut(C_p, breaks=cut,right=TRUE,
include.lowest = FALSE, labels=c(0,0,0.031,0.061,0.201,0.201))))
I_hi <- as.numeric(as.character(cut(C_p, breaks=cut,right=TRUE,
include.lowest = FALSE, labels=c(50,50,100,250,500,500))))
I_lo <- as.numeric(as.character(cut(C_p, breaks=cut,right=TRUE,
include.lowest = FALSE, labels=c(0,0,51,101,251,251))))
I_p <- (I_hi-I_lo)/(BP_hi-BP_lo) * (C_p - BP_lo) + I_lo
return(I_p)
}
# PM10, PM2.5의 이동평균을 구하기 위한 함수 정의
C12_cal <- function(PM){
C12 <- c()
for (i in (1:length(PM))){
if (i<12){
tmp <- sum(PM[1:i])/i
}else{
tmp <- sum(PM[(i-11):i])/12
}
C12[i] <- tmp
}
return (C12)
}
C_ai_cal <- function(C_i,M,C12){
if (C_i < M){
C_ai <- C_i
}else if(0.9<= (C_i/C12) && (C_i/C12) <=1.7){
C_ai <- 0.75*C_i
}else {
C_ai <- C_i
}
return (C_ai)
}
PM_cal <- function(PM,m,PM_C12){
M=m
C24E=c()
for (i in (1:length(PM))){
if (i<4){
C4 <-0
for (j in (i:1)){
C4 <- C4+ C_ai_cal(PM[j],M,PM_C12[j])
}
C4/i
} else{
C4 <- sum(C_ai_cal(PM[i],M,PM_C12[i]),C_ai_cal(PM[i-1],M,PM_C12[i-1]),
C_ai_cal(PM[i-2],M,PM_C12[i-2]),C_ai_cal(PM[i-3],M,PM_C12[i-3]))/4
}
C12<-PM_C12[i]
C24E[i] = (C12*12+C4*12)/24
}
return (C24E)
}
PM10_I_p <- function(C_p){
cut <- c(-Inf,0,30,80,150,600,Inf)
BP_hi <- as.numeric(as.character(cut(C_p, breaks=cut,right=TRUE,
include.lowest = FALSE,
labels=c(30,30,80,150,600,600))))
BP_lo <- as.numeric(as.character(cut(C_p, breaks=cut,right=TRUE,
include.lowest = FALSE,
labels=c(0,0,31,81,151,151))))
I_hi <- as.numeric(as.character(cut(C_p, breaks=cut,right=TRUE,
include.lowest = FALSE,
labels=c(50,50,100,250,500,500))))
I_lo <- as.numeric(as.character(cut(C_p, breaks=cut,right=TRUE,
include.lowest = FALSE,
labels=c(0,0,51,101,251,251))))
I_p <- (I_hi-I_lo)/(BP_hi-BP_lo) * (C_p - BP_lo) + I_lo
return(I_p)
}
PM2.5_I_p <- function(C_p){
cut <- c(-Inf,0,15,35,75,500,Inf)
BP_hi <- as.numeric(as.character(cut(C_p, breaks=cut,right=TRUE,
include.lowest = FALSE, labels=c(15,15,35,75,500,500))))
BP_lo <- as.numeric(as.character(cut(C_p, breaks=cut,right=TRUE,
include.lowest = FALSE, labels=c(0,0,16,36,76,76))))
I_hi <- as.numeric(as.character(cut(C_p, breaks=cut,right=TRUE,
include.lowest = FALSE, labels=c(50,50,100,250,500,500))))
I_lo <- as.numeric(as.character(cut(C_p, breaks=cut,right=TRUE,
include.lowest = FALSE, labels=c(0,0,51,101,251,251))))
I_p <- (I_hi-I_lo)/(BP_hi-BP_lo) * (C_p - BP_lo) + I_lo
return(I_p)
}
PM10_C12<-C12_cal(data$PM10)
PM10_C_p <- PM_cal(data$PM10,70,PM10_C12)
PM2.5_C12 <- C12_cal(data$PM2.5)
PM2.5_C_p <- PM_cal(data$PM2.5,30,PM2.5_C12)
data <- data %>%
bind_cols("SO2_I_p" = SO2_I_p(data$SO2)) %>%
bind_cols("CO_I_p" = CO_I_p(data$CO)) %>%
bind_cols("O3_I_p" = O3_I_p(data$O3)) %>%
bind_cols("NO2_I_p" = NO2_I_p(data$NO2)) %>%
bind_cols("PM10_I_p" = PM10_I_p(PM10_C_p)) %>%
bind_cols("PM2.5_I_p" = PM2.5_I_p(PM2.5_C_p))
CAI_table <- data %>%
select(ends_with("I_p")) %>%
mutate(BAD = rowSums(. >100)) %>%
mutate(CAI = apply(., 1, max) + case_when(BAD>=3 ~ 75, BAD>=2 ~ 50,TRUE ~ 0)) %>%
mutate(CAI_index = case_when(CAI>250 ~ 3, CAI>100 ~ 2,
CAI>50 ~ 1, TRUE ~ 0)) %>%
select(starts_with("CAI"))
data <- data %>%
bind_cols(CAI_table)
head(data[c(11:18)],5)
| SO2_I_p | CO_I_p | O3_I_p | NO2_I_p | PM10_I_p | PM2.5_I_p | CAI | CAI_index |
|---|---|---|---|---|---|---|---|
| 4.00 | 7.5 | 68.44068 | 2.666667 | 64.00000 | 88.71711 | 88.71711 | 1 |
| 4.00 | 7.5 | 68.44068 | 2.833333 | 68.75000 | 103.38782 | 103.38782 | 2 |
| 4.25 | 7.5 | 67.61017 | 2.833333 | 84.66667 | 131.82942 | 131.82942 | 2 |
| 4.25 | 7.5 | 66.77966 | 3.333333 | 44.58333 | 66.44682 | 66.77966 | 1 |
| 4.00 | 7.5 | 65.11864 | 3.000000 | 39.95833 | 64.79737 | 65.11864 | 1 |
3.2. Timestep-wise Visualization
- 시구간별 시각화 및 분석
3.2.1. Hourly
# 시간대(주간: 07~18, 야간: 19~06)에 따른 CAI 지수 분포
CAI_hourly <- data %>%
mutate(time_tmp = case_when(
06<hour & hour<19 ~ "daytime", TRUE ~ "nighttime")) %>%
group_by(year,month,day,time_tmp) %>%
summarise(mean_CAI=mean(CAI)) %>%
mutate(CAI_idx = case_when(mean_CAI>250 ~ 3, mean_CAI>100 ~ 2,
mean_CAI>50 ~ 1, TRUE ~ 0)) %>% # 해당 시간대의 평균 오염도
ungroup()
# 시간에 따른 오염도의 분포는 거의 차이가 없음을 확인
CAI_hourly %>%
group_by(time_tmp,CAI_idx)%>%
tally()
`summarise()` has grouped output by 'year', 'month', 'day'. You can override using the `.groups` argument.
| time_tmp | CAI_idx | n |
|---|---|---|
| daytime | 0 | 100 |
| daytime | 1 | 886 |
| daytime | 2 | 93 |
| daytime | 3 | 17 |
| nighttime | 0 | 73 |
| nighttime | 1 | 895 |
| nighttime | 2 | 115 |
| nighttime | 3 | 13 |
3.2.2. Daily
### 일단위: 일평균 CAI 지수의 분포
CAI_daily <- data %>%
group_by(year,month,day) %>%
summarise_at(.vars="CAI", .funs=mean) %>%
ungroup() %>%
mutate(CAI_idx = case_when(CAI>250 ~ 3, CAI>100 ~ 2,
CAI>50 ~ 1, TRUE ~ 0))
summary(factor(CAI_daily$CAI_idx))
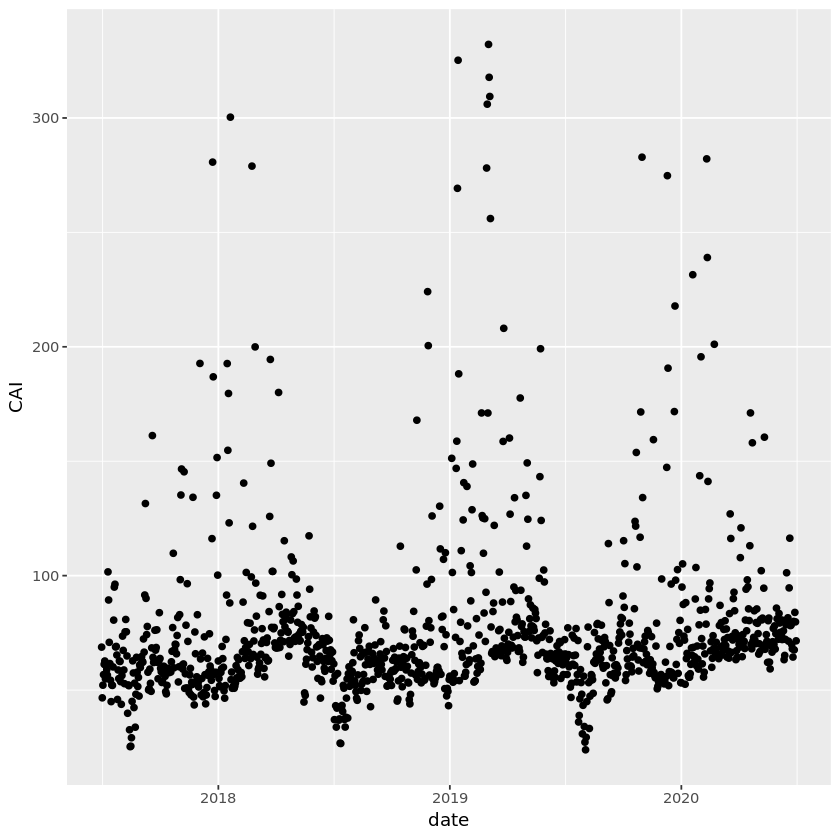
# 평균 수준보다 오염도가 높은 날들은 연중 특정 시기에 집중되어있음
CAI_daily %>%
unite("date",1:3,sep="/") %>%
mutate_at("date",as.Date) %>%
ggplot() +
geom_point(mapping=aes(x=date,y=CAI))
3.2.3. Montly
### 월단위: 오염 수준 나쁨 이상인 "일수" 확인
CAI_monthly <- CAI_daily %>%
group_by(year,month) %>%
summarise(mean_CAI = mean(CAI),sum_CAI_idx = sum(CAI_idx>1)) %>%
mutate(m_tmp = case_when(month<10 ~ paste("0",as.character(month),sep=""),
TRUE ~ paste(as.character(month))))%>%
mutate(y_tmp=as.character(year)) %>%
unite(date,y_tmp,m_tmp,sep="")
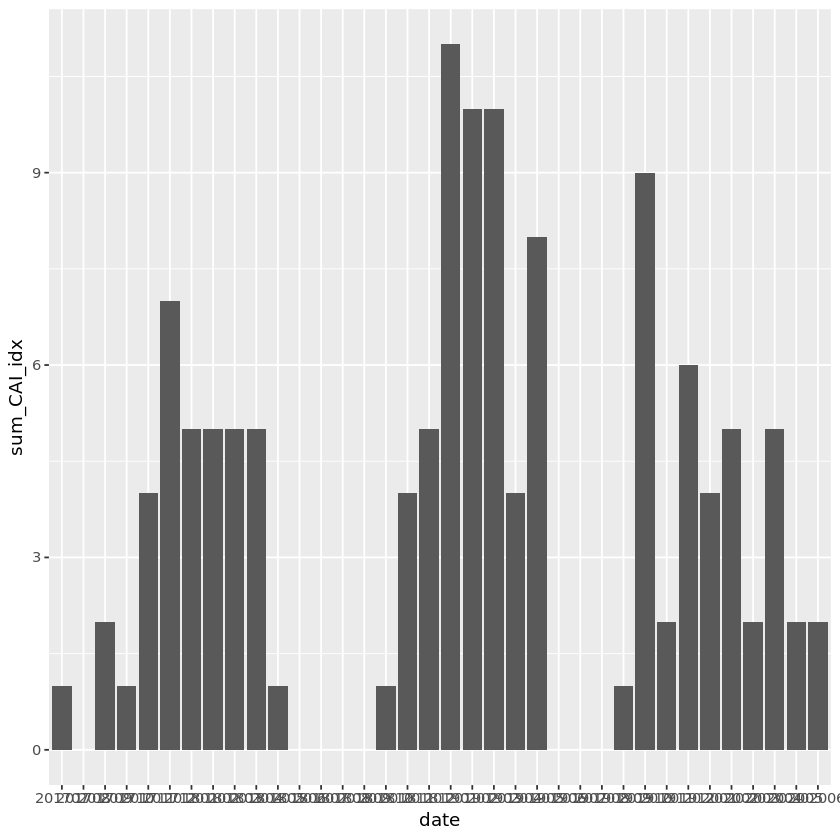
# 6월~9월은 장마 영향으로 추정. 겨울~봄에 집중적.
CAI_monthly %>%
ggplot() +
geom_col(mapping=aes(x=date,y=sum_CAI_idx))
`summarise()` has grouped output by 'year'. You can override using the `.groups` argument.
3.2.4. Quarterly
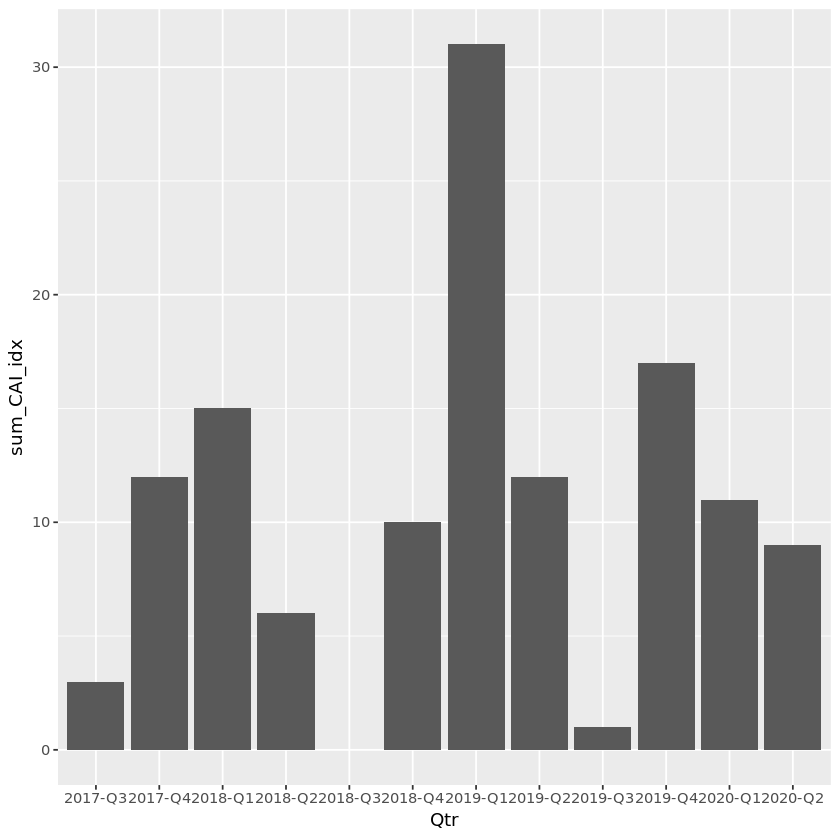
### 분기 단위
CAI_qtr <- CAI_monthly %>%
mutate(qtr_tmp = case_when(
month < 4 ~ "Q1", month < 7 ~ "Q2", month < 10 ~ "Q3", TRUE ~ "Q4")) %>%
mutate(y_tmp=as.character(year)) %>%
unite(Qtr, y_tmp, qtr_tmp, sep="-") %>%
group_by(Qtr) %>%
summarise(mean_CAI = mean(mean_CAI), sum_CAI_idx = sum(sum_CAI_idx))
CAI_qtr %>%
ggplot() +
geom_col(aes(x=Qtr,y=sum_CAI_idx))
3.2.5. Half-yearly
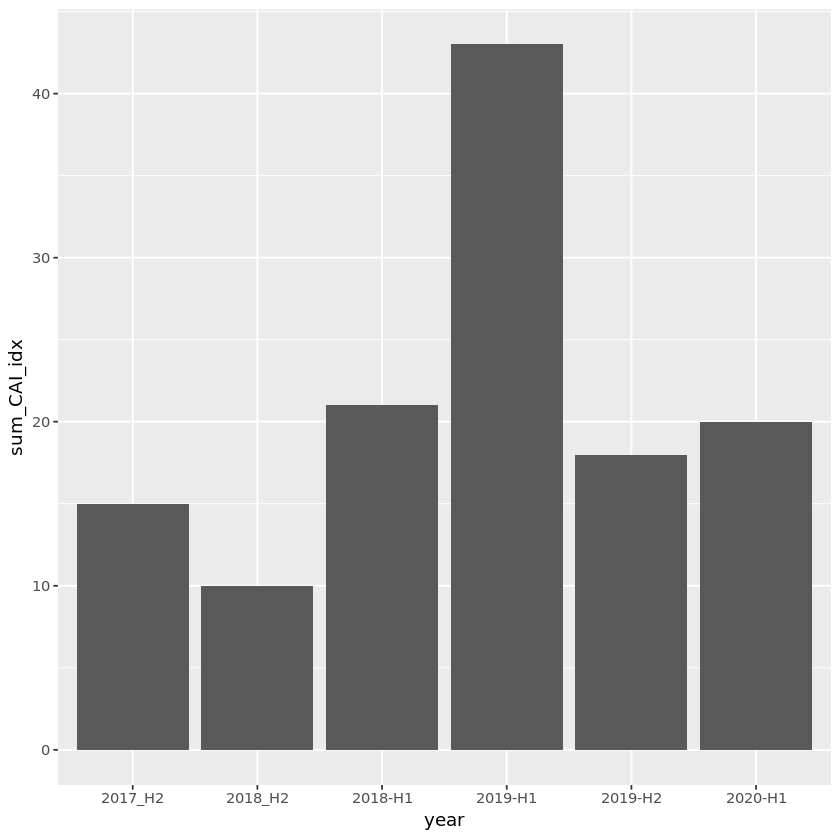
### 반기 단위: 2019년 상반기가 매우 심한 것이었음을 알 수 있음
CAI_half <- CAI_monthly %>%
transform(date=as.integer(date)) %>%
mutate(year = case_when(
date < 201801 ~ "2017_H2", date < 201807 ~ "2018-H1",
date < 201901 ~ "2018_H2", date < 201907 ~ "2019-H1",
date < 202001 ~ "2019-H2", TRUE ~ "2020-H1")) %>%
group_by(year) %>%
summarise(mean_CAI = mean(mean_CAI), sum_CAI_idx = sum(sum_CAI_idx))
CAI_half %>%
ggplot()+
geom_col(aes(x=year,y=sum_CAI_idx))
4. Summary
대기오염도는 대체적으로 여름보다 겨울에 높았고, 2019년이 특히 심했다는 것을 알 수 있다. 2020년을 기준으로 비교했을 때, 코로나의 영향은 거의 없었던 것으로 추정된다.