category content title
count 10686 10686 10686
unique 7 10302 10124
top 정치개혁 개인회생 36개월 단축소급 전국 적용을 위해 춘천지방법원의 법원에 바란다에 글을 올... 경남제약
freq 3094 16 21
# tokenize
from konlpy.tag import Okt
okt = Okt() #형태소 분석기
tokenized_data = []
stopwords = ['의','가','이','은','들','는','좀','잘','걍','과','도','를','으로','자','에','와','한','하다']
for sentence in train_data['document']:
temp_X = okt.morphs(sentence, norm=True, stem=True) # 형태소 추출
temp_X = [word for word in temp_X if not word in stopwords] # 불용어 제거
tokenized_data.append(temp_X)
x_train=tokenized_data
okt = Okt() #형태소 분석기
tokenized_data = []
stopwords = ['의','가','이','은','들','는','좀','잘','걍','과','도','를','으로','자','에','와','한','하다']
for sentence in test_data['document']:
temp_X = okt.morphs(sentence, norm=True, stem=True) # 형태소 추출 - 토큰화 #norm=True : 근사어
temp_X = [word for word in temp_X if not word in stopwords] # 불용어 제거 #https://www.ranks.nl/stopwords/korean
tokenized_data.append(temp_X)
x_test=tokenized_data
from tensorflow.keras.preprocessing.text import Tokenizer
tokenizer = Tokenizer()
tokenizer.fit_on_texts(x_train)
threshold = 3
total_cnt = len(tokenizer.word_index) # 단어의 수
rare_cnt = 0 # 등장 빈도수가 threshold보다 작은 단어의 개수를 카운트
total_freq = 0 # 훈련 데이터의 전체 단어 빈도수 총 합
rare_freq = 0 # 등장 빈도수가 threshold보다 작은 단어의 등장 빈도수의 총 합
# 단어와 빈도수의 쌍(pair)을 key와 value로 받는다.
for key, value in tokenizer.word_counts.items():
total_freq = total_freq + value
# 단어의 등장 빈도수가 threshold보다 작으면
if(value < threshold):
rare_cnt = rare_cnt + 1
rare_freq = rare_freq + value
print('단어 집합(vocabulary)의 크기 :',total_cnt)
print('등장 빈도가 %s번 이하인 희귀 단어의 수: %s'%(threshold - 1, rare_cnt))
print("단어 집합에서 희귀 단어의 비율:", (rare_cnt / total_cnt)*100)
print("전체 등장 빈도에서 희귀 단어 등장 빈도 비율:", (rare_freq / total_freq)*100)
단어 집합(vocabulary)의 크기 : 34537
등장 빈도가 2번 이하인 희귀 단어의 수: 15483
단어 집합에서 희귀 단어의 비율: 44.830182123519705
전체 등장 빈도에서 희귀 단어 등장 빈도 비율: 1.1132793250941202
drop_train = [index for index, sentence in enumerate(X_train) if len(sentence) < 1]
drop_test = [index for index, sentence in enumerate(X_test) if len(sentence) < 1]
X_train = np.delete(X_train, drop_train, axis=0)
y_train = np.delete(y_train, drop_train, axis=0)
print(len(X_train))
print(len(y_train))
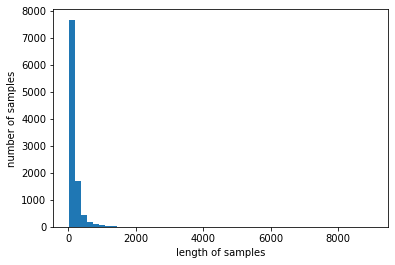
리뷰의 최대 길이 : 9032
리뷰의 평균 길이 : 170.45791670711583
전체 샘플 중 길이가 600 이하인 샘플의 비율: 96.02951169789341
t={'경제민주화': 1, '교통/건축/국토': 2, '보건복지': 3, '육아/교육': 4, '인권/성평등': 5, '일자리': 6, '정치개혁': 7}
print(t['보건복지'])
index1=np.zeros([10301,7])
for i in range(len(y_train)):
index1[i][t[y_train[i]]-1]=1
y_train=index1
index1=np.zeros([1158,7])
for i in range(len(y_test)):
index1[i][t[y_test[i]]-1]=1
y_test=index1
print(y_train.shape,y_test.shape)
(10301, 600)
(1158, 600)
(10301, 7)
(1158, 7)
19055
model = Sequential()
model.add(Embedding(vocab_size, 128))
model.add(LSTM(128))
model.add(Dense(7, activation='sigmoid'))
es = EarlyStopping(monitor='val_loss', mode='min', verbose=2, patience=4)
mc = ModelCheckpoint('best_model.h5', monitor=f1, mode='max', verbose=2, save_best_only=True)
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['acc',f1])
model.fit(X_train, y_train, epochs=15, callbacks=[es, mc], batch_size=512, validation_split=0.2)
Epoch 1/15
17/17 [==============================] - 39s 2s/step - loss: 1.8842 - acc: 0.2830 - f1_score: 0.2583 - val_loss: 1.7326 - val_acc: 0.3081 - val_f1_score: 0.2726
WARNING:tensorflow:Can save best model only with <tensorflow_addons.metrics.f_scores.F1Score object at 0x7f1bd3f444f0> available, skipping.
Epoch 2/15
17/17 [==============================] - 38s 2s/step - loss: 1.6177 - acc: 0.4615 - f1_score: 0.3981 - val_loss: 1.5555 - val_acc: 0.4639 - val_f1_score: 0.3776
WARNING:tensorflow:Can save best model only with <tensorflow_addons.metrics.f_scores.F1Score object at 0x7f1bd3f444f0> available, skipping.
Epoch 3/15
17/17 [==============================] - 38s 2s/step - loss: 1.3590 - acc: 0.5495 - f1_score: 0.4018 - val_loss: 1.3879 - val_acc: 0.5075 - val_f1_score: 0.4232
WARNING:tensorflow:Can save best model only with <tensorflow_addons.metrics.f_scores.F1Score object at 0x7f1bd3f444f0> available, skipping.
Epoch 4/15
17/17 [==============================] - 38s 2s/step - loss: 1.1364 - acc: 0.6211 - f1_score: 0.4351 - val_loss: 1.3140 - val_acc: 0.5303 - val_f1_score: 0.4173
WARNING:tensorflow:Can save best model only with <tensorflow_addons.metrics.f_scores.F1Score object at 0x7f1bd3f444f0> available, skipping.
Epoch 5/15
17/17 [==============================] - 38s 2s/step - loss: 0.9084 - acc: 0.7212 - f1_score: 0.4893 - val_loss: 1.1852 - val_acc: 0.6487 - val_f1_score: 0.4386
WARNING:tensorflow:Can save best model only with <tensorflow_addons.metrics.f_scores.F1Score object at 0x7f1bd3f444f0> available, skipping.
Epoch 6/15
17/17 [==============================] - 38s 2s/step - loss: 0.7336 - acc: 0.7920 - f1_score: 0.5183 - val_loss: 1.1071 - val_acc: 0.6473 - val_f1_score: 0.4536
WARNING:tensorflow:Can save best model only with <tensorflow_addons.metrics.f_scores.F1Score object at 0x7f1bd3f444f0> available, skipping.
Epoch 7/15
17/17 [==============================] - 39s 2s/step - loss: 0.5796 - acc: 0.8381 - f1_score: 0.5395 - val_loss: 1.0900 - val_acc: 0.6458 - val_f1_score: 0.4837
WARNING:tensorflow:Can save best model only with <tensorflow_addons.metrics.f_scores.F1Score object at 0x7f1bd3f444f0> available, skipping.
Epoch 8/15
17/17 [==============================] - 38s 2s/step - loss: 0.4641 - acc: 0.8757 - f1_score: 0.5575 - val_loss: 0.9854 - val_acc: 0.6982 - val_f1_score: 0.4781
WARNING:tensorflow:Can save best model only with <tensorflow_addons.metrics.f_scores.F1Score object at 0x7f1bd3f444f0> available, skipping.
Epoch 9/15
17/17 [==============================] - 38s 2s/step - loss: 0.3588 - acc: 0.9039 - f1_score: 0.5759 - val_loss: 1.2205 - val_acc: 0.6458 - val_f1_score: 0.4993
WARNING:tensorflow:Can save best model only with <tensorflow_addons.metrics.f_scores.F1Score object at 0x7f1bd3f444f0> available, skipping.
Epoch 10/15
17/17 [==============================] - 38s 2s/step - loss: 0.3082 - acc: 0.9181 - f1_score: 0.5908 - val_loss: 1.0990 - val_acc: 0.6870 - val_f1_score: 0.5031
WARNING:tensorflow:Can save best model only with <tensorflow_addons.metrics.f_scores.F1Score object at 0x7f1bd3f444f0> available, skipping.
Epoch 11/15
17/17 [==============================] - 39s 2s/step - loss: 0.2331 - acc: 0.9408 - f1_score: 0.6076 - val_loss: 1.8883 - val_acc: 0.5793 - val_f1_score: 0.4935
WARNING:tensorflow:Can save best model only with <tensorflow_addons.metrics.f_scores.F1Score object at 0x7f1bd3f444f0> available, skipping.
Epoch 12/15
17/17 [==============================] - 39s 2s/step - loss: 0.2625 - acc: 0.9380 - f1_score: 0.6111 - val_loss: 1.3714 - val_acc: 0.6642 - val_f1_score: 0.5215
WARNING:tensorflow:Can save best model only with <tensorflow_addons.metrics.f_scores.F1Score object at 0x7f1bd3f444f0> available, skipping.
Epoch 00012: early stopping
<keras.callbacks.History at 0x7f1bf1402a60>
37/37 [==============================] - 6s 149ms/step - loss: 1.1846 - acc: 0.6986 - f1_score: 0.5419
[1.1846439838409424,
0.6986182928085327,
array([0.5124555 , 0.59907836, 0.48712873, 0.45633796, 0.5854922 ,
0.4855967 , 0.6674057 ], dtype=float32)]