cs231n - Lecture 13. Self-Supervised Learning
Self-Supervised Learning
Generative vs. Self-supervised Learning
- Both aim to learn from data without manual label annotation
- Generative learning aims to model data distribution $p_{data}(x)$,
e.g., generating realistic images. - Self-supervised learning methods solve “pretext” tasks that produce good features for downstream tasks.
- Learn with supervised learning objectives, e.g., classification, regression.
- Labels of these pretext tasks are generated automatically.
Self-supervised pretext tasks
- Example: learn to predict image transformations / complete corrupted images;
e.g. image completion, rotation prediction, “jigsaw puzzle”, coloriztaion.
- Solving the pretext tasks allow the model to learn good features.
- We can automatically generate labels for the pretext tasks.
- Learning to generate pixel-level details is often unnecessary; learn high-level semantic features with pretext tasks instead(only encode high-level features sufficient enough to distinguish different objects, Contrastive Methods): Epstein, 2016
How to evaluate a self-supervised learning method?
- Self-supervised learning:
With lots of unlabeled data, learn good feature extractors from self-supervised pretext tasks, e.g., predicting image rotations. - Supervised Learning:
With small amount of labeled data on the target task, attach a shallow network on the feature extractor; train the shallow network and evaluate on the target task, e.g., classification, detection.
Pretext tasks from image transformations
- Predict Rotations
Gidaris et al., 2018 - (Paper Review)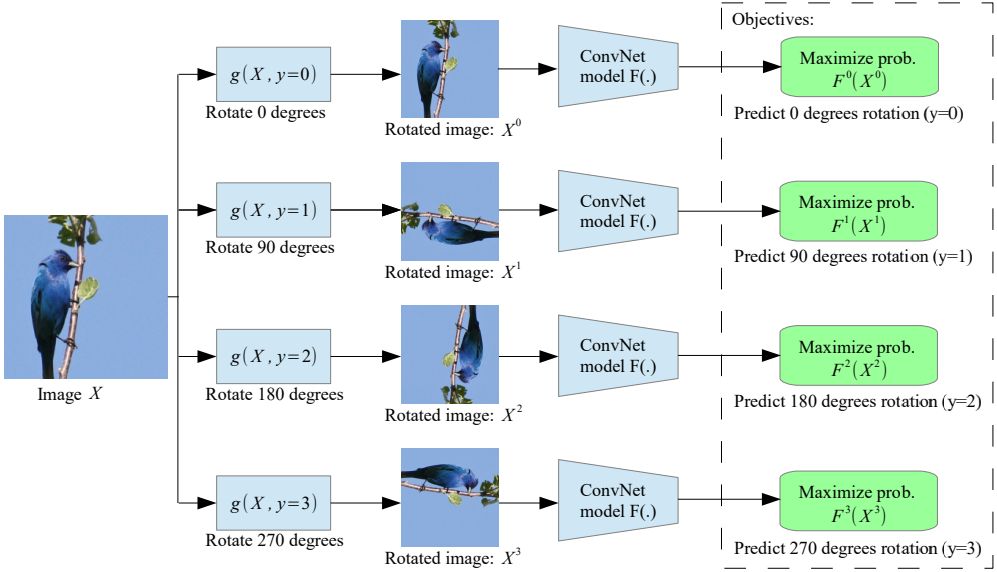
- Predict Relative Patch Locations
Doersch et al., 2015
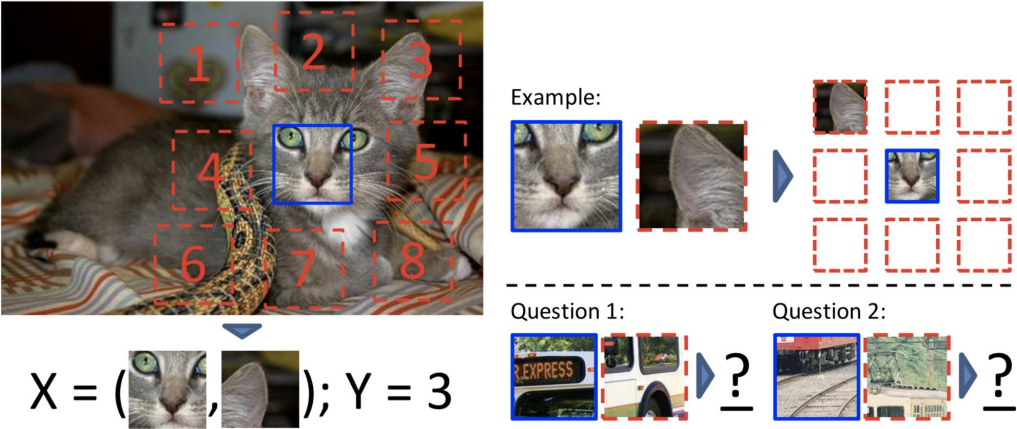
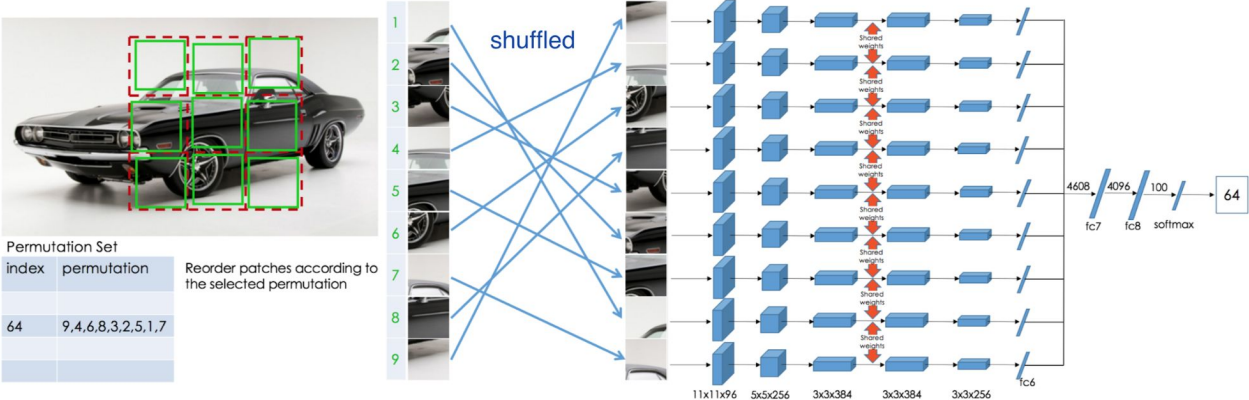
- Solving “jigsaw puzzles”; shuffled patches
Noroozi & Favaro, 2016
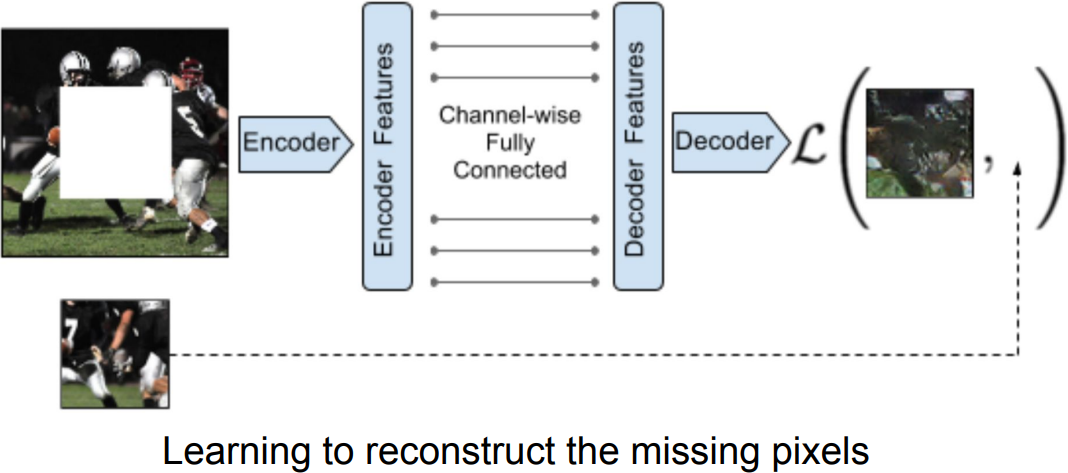
- Predict Missing Pixels(Inpainting); encoder-decoder
Pathak et al., 2016
- Image Coloring; Split-brain Autoencoder
Richard Zhang/ Phillip Isola
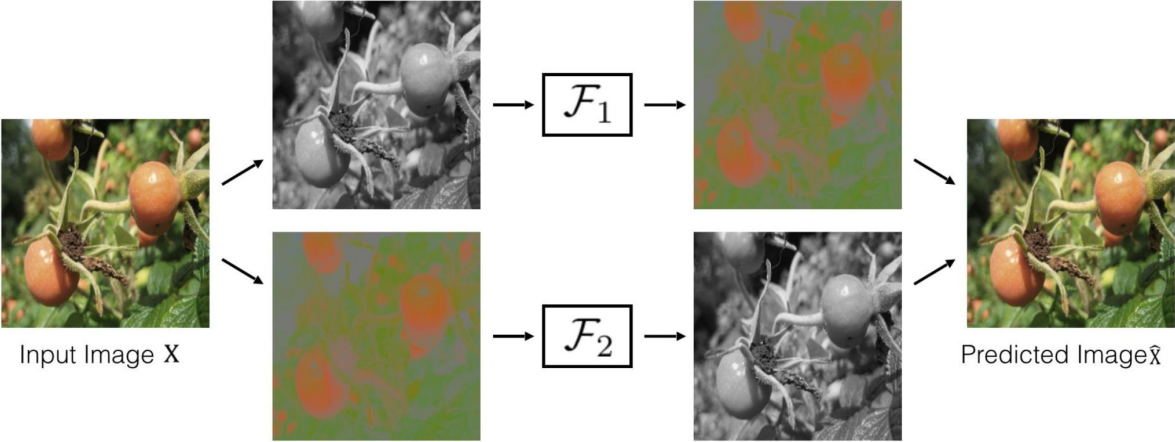
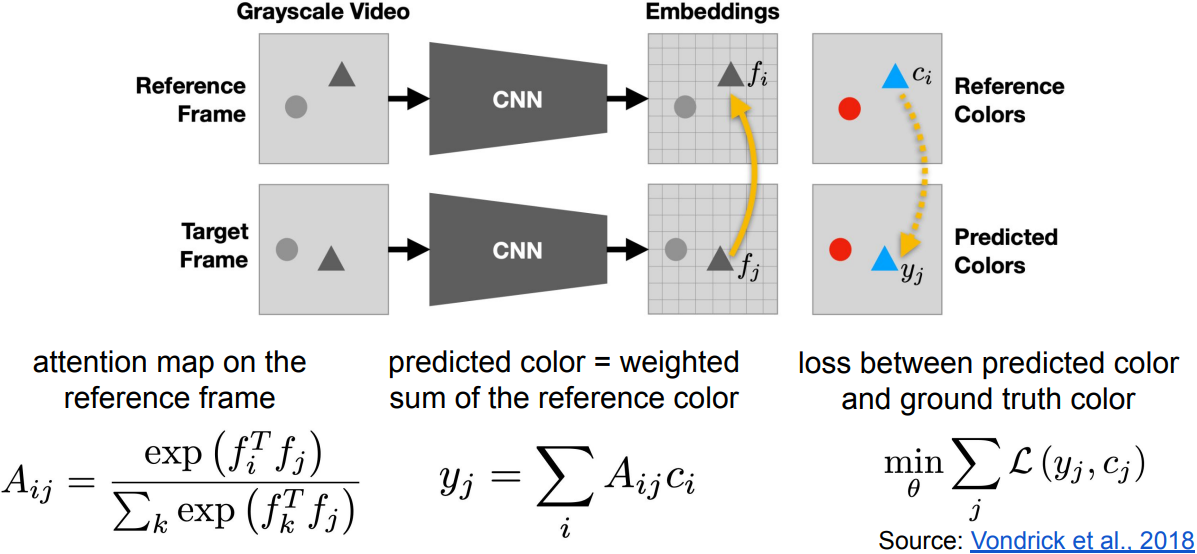
- Video Coloring; from t=0 reference frame to the later frames
Summary: Pretext tasks
- Pretext tasks focus on “visual common sense”; by image transformations, can learn without supervision(big labeled data).
- The models are forced learn good features about natural images, e.g., semantic representation of an object category, in order to solve the pretext tasks.
- We don’t care about the performance of these pretext tasks, but rather how useful the learned features are for downstream tasks.
- $\color{red}{Problems}$: 1) coming up with individual pretext tasks is tedious, and 2) the learned representations may not be general; tied to a specific pretext task.
Contrastive Representation Learning
For a more general pretext task,
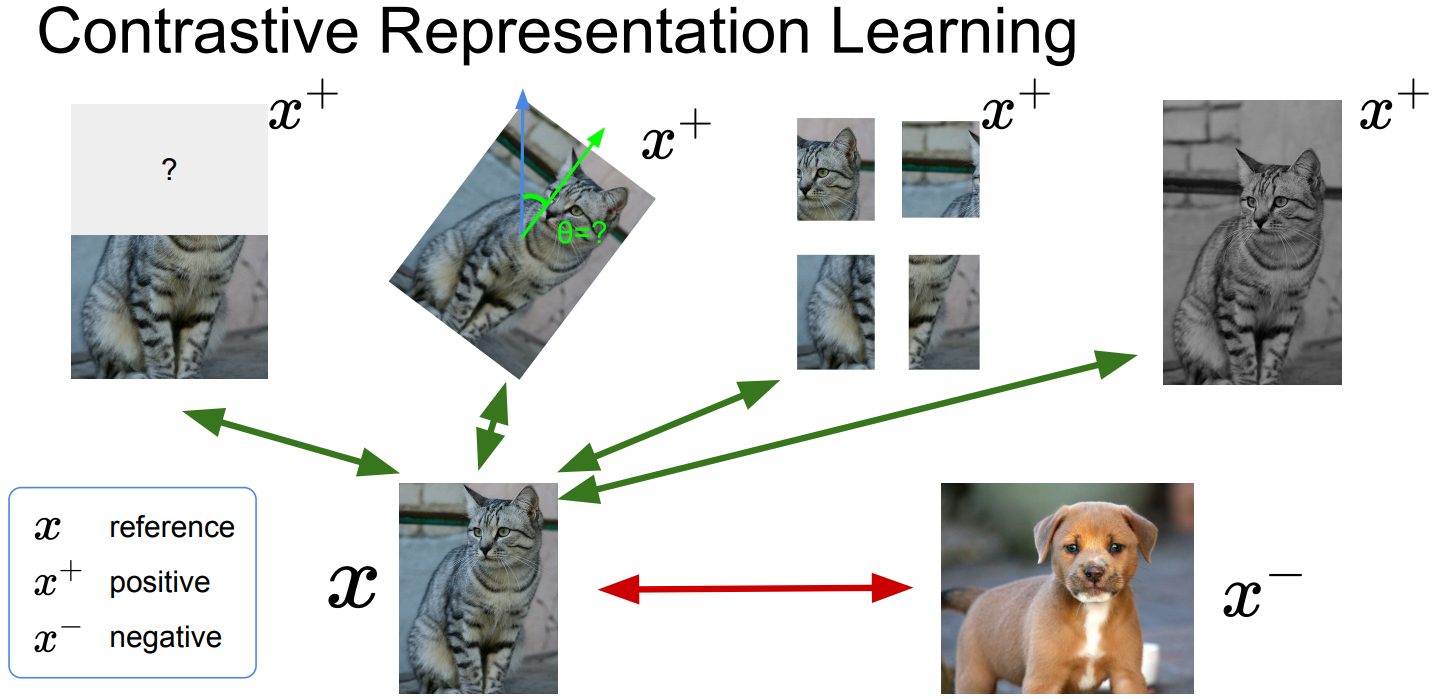
A formulation of contrastive learning
-
What we want:
$\mbox{score}(f(x), f(x^+)) » score(f(x), f(x^-))$
x: reference sample, x+: positive sample, x-: negative sample
Given a chosen score function, we aim to learn an encoder function f that yields high score for positive pairs and low scores for negative pairs. -
Loss function given 1 positive sample and N-1 negative samples:
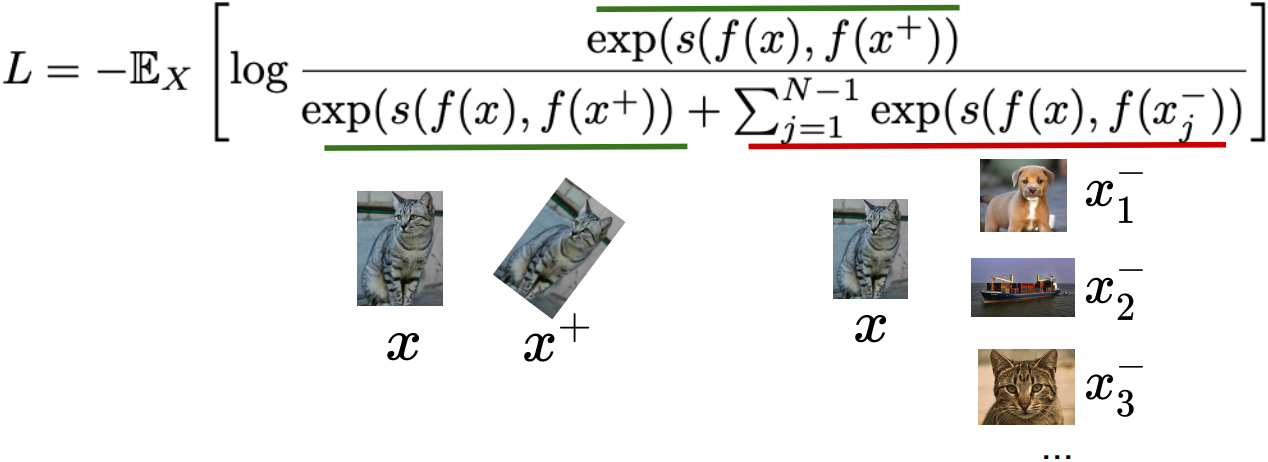
seems familiar with Cross entropy loss for a N-way softmax classifier!
i.e., learn to find the positive sample from the N samples- Commonly known as the InfoNCE loss(van den Oord et al., 2018)
A lower bound on the mutual information between $f(x)$ and $f(x^+)$
\(\rightarrow MI[f(x), f(x^+)] - \log(N) \ge -L\)
The larger the negative sample size(N), the tighter the bound
- Commonly known as the InfoNCE loss(van den Oord et al., 2018)
SimCLR: A Simple Framework for Contrastive Learning
- Chen et al., 2020
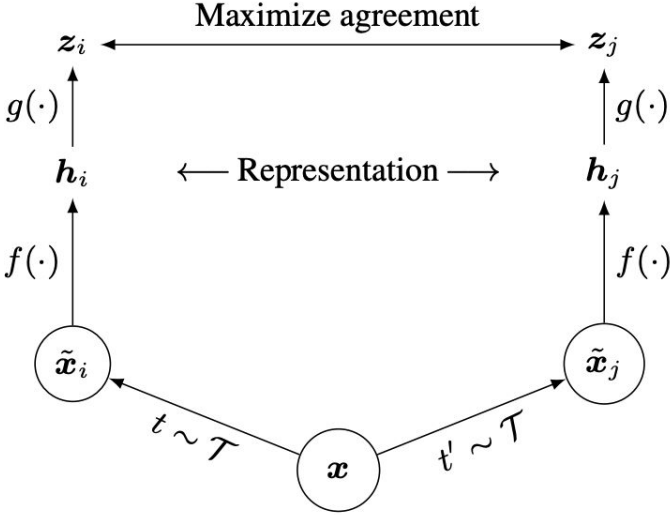
- Cosine similarity as the score function:
\(s(u, v) = \frac{u^T v}{\lVert u \rVert \lVert v \rVert}\) - Use a projection network h(.) to project features to a space where contrastive learning is applied.
-
Generate positive samples through data augmentation:
random cropping, random color distortion, and random blur.
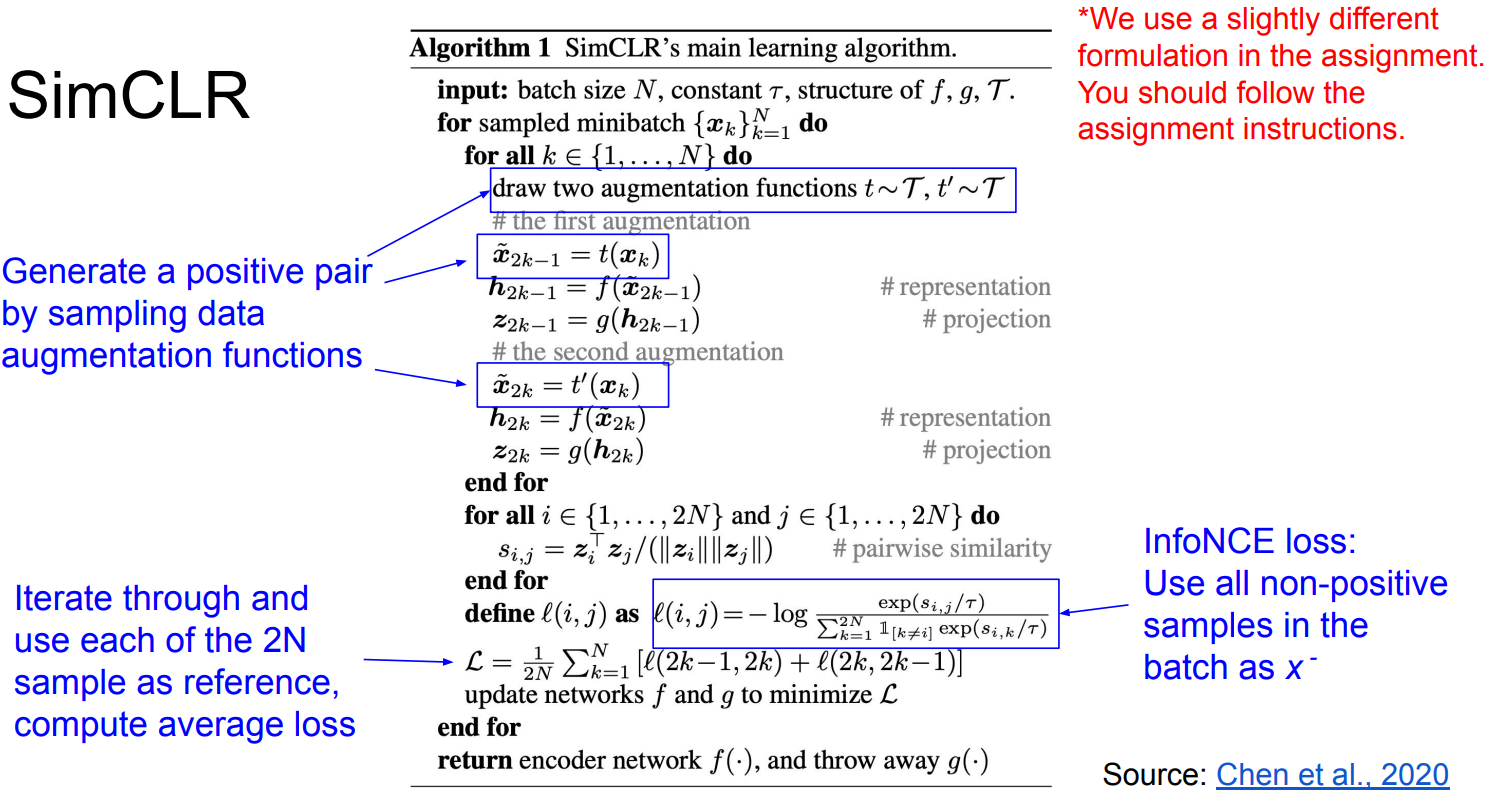
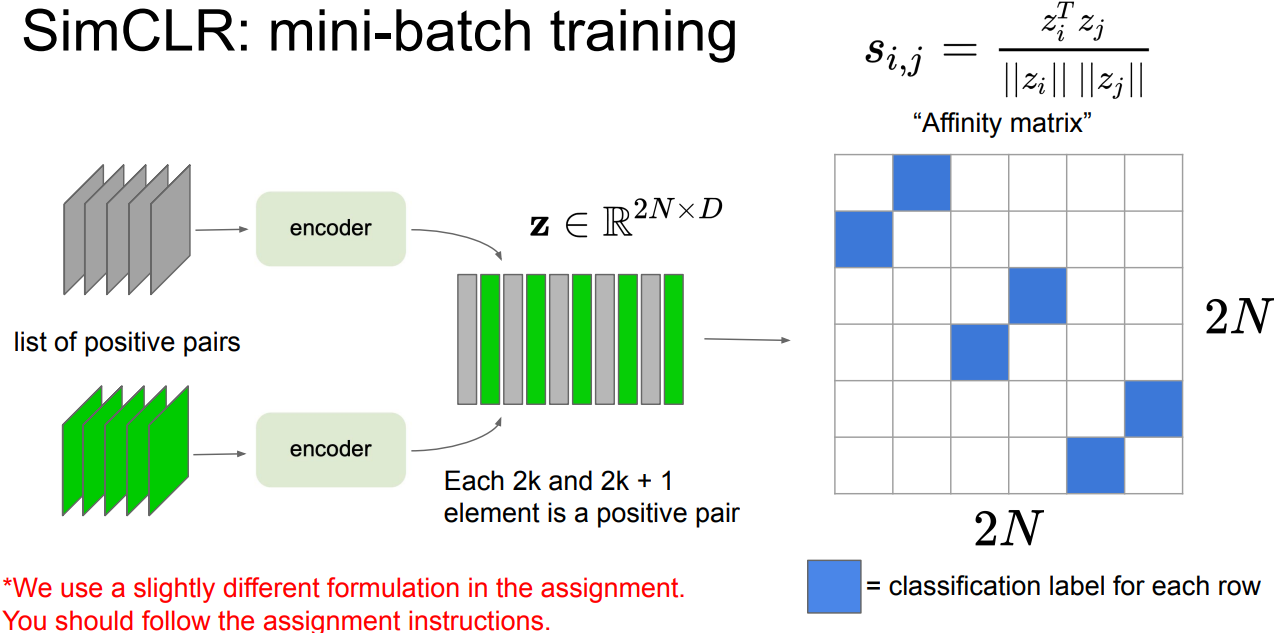
- Evaluate: Freeze feature encoder, train(finetune) on a supervised downstream task
SimCLR design choices: Projection head($z=g(.)$)
Linear / non-linear projection heads improve representation learning.
- A possible explanation:
- contrastive learning objective may discard useful information for downstream tasks.
- representation space z is trained to be invariant to data transformation.
- by leveraging the projection head g(.), more information can be preserved in the h representation space
SimCLR design choices: Large batch size
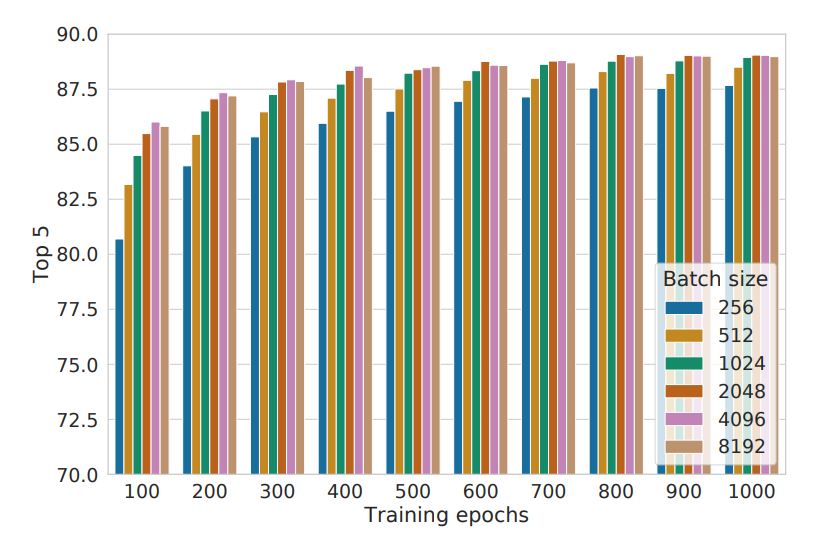
Large training batch size is crucial for SimCLR, but it causes large memory footprint during backpropagation; requires distributed training on TPUs.
Momentum Contrastive Learning (MoCo)
- He et al., 2020
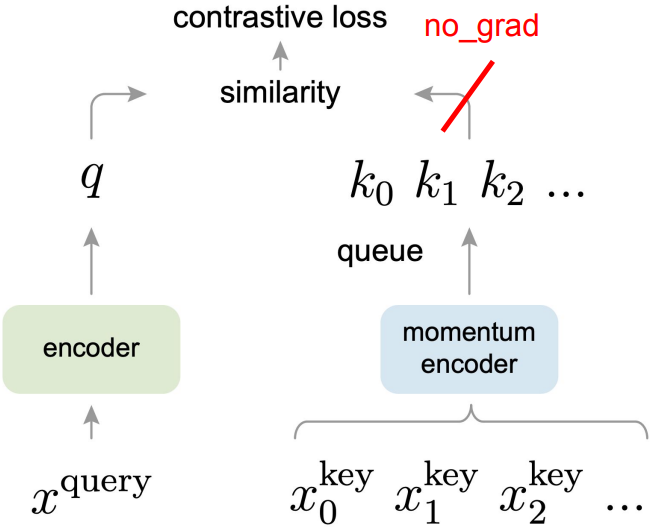
- Key differences to SimCLR:
- Keep a running queue of keys (negative samples).
- Compute gradients and update the encoder only through the queries.
- Decouple min-batch size with the number of keys: can support a large number of negative samples.
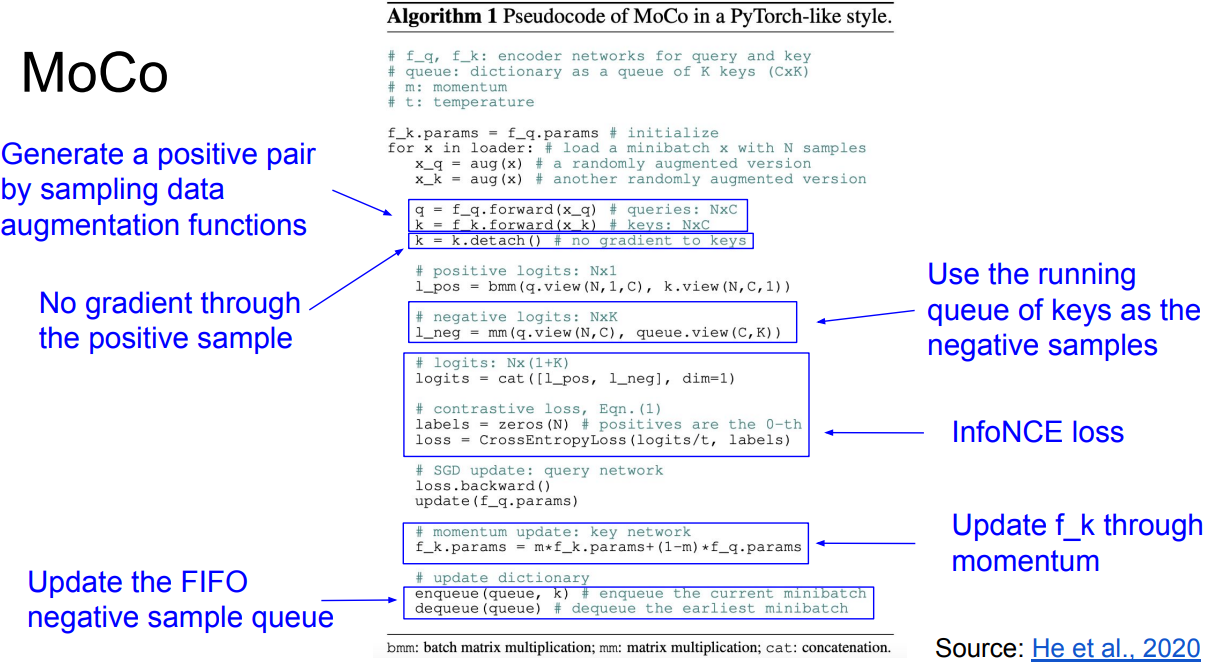
MoCo V2
- Chen et al., 2020
- A hybrid of ideas from SimCLR and MoCo:
From SimCLR: non-linear projection head and strong data augmentation.
From MoCo: momentum-updated queues that allow training on a large number of negative samples (no TPU required). - Key takeaways(vs. SimCLR, MoCo V1):
- Non-linear projection head and strong data augmentation are crucial for contrastive learning.
- Decoupling mini-batch size with negative sample size allows MoCo-V2 to outperform SimCLR with smaller batch size (256 vs. 8192).
- Achieved with much smaller memory footprint.
Instance vs. Sequence Contrastive Learning
- Instance-level contrastive learning:
Based on positive & negative instances.
E.g., SimCLR, MoCo - Sequence-level contrastive learning:
Based on sequential / temporal orders.
E.g., Contrastive Predictive Coding (CPC)
Contrastive Predictive Coding (CPC)
- van den Oord et al., 2018
- Contrastive: contrast between “right” and “wrong” sequences using contrastive learning.
- Predictive: the model has to predict future patterns given the current context.
- Coding: the model learns useful feature vectors, or “code”, for downstream tasks, similar to other context self-supervised methods.
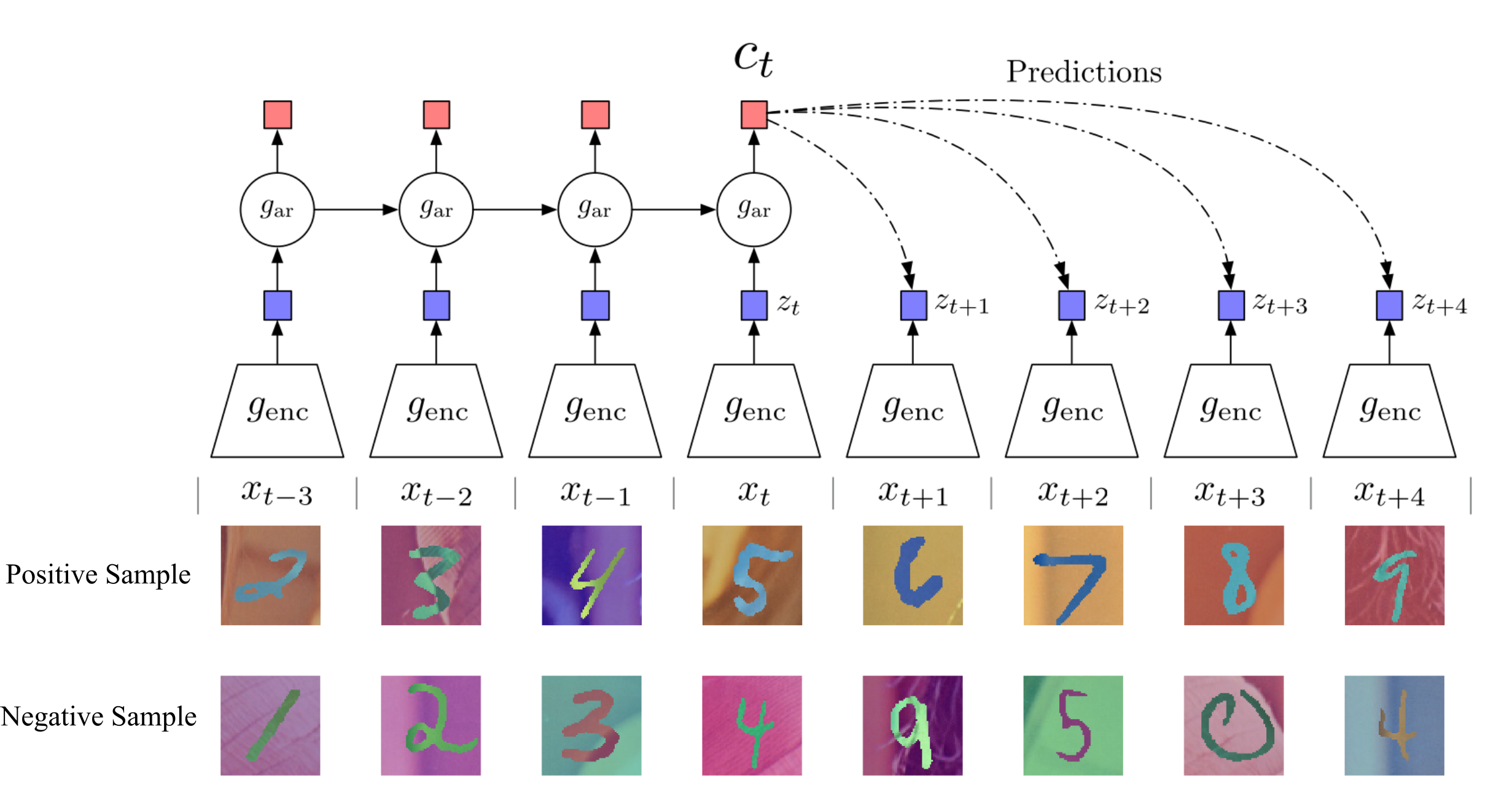
- Encode all samples in a sequence into vectors $z_t = g_{\mbox{enc}}(x_t)$
- Summarize context (e.g., half of a sequence) into a context code $c_t$ using an auto-regressive model ($g_{\mbox{ar}}$). The original paper uses GRU-RNN here.
- Compute InfoNCE loss between the context $c_t$ and future code $z_{t+k}$ using the following time-dependent score funtion: $s_k(z_{t+k}, c_t) = z_{t+k}^T W_k c_t$, where $W_k$ is a trainable matrix.
- Summary(CPC):
Contrast “right” sequence with “wrong” sequence.
InfoNCE loss with a time-dependent score function.
Can be applied to a variety of learning problems, but not as effective in learning image representations compared to instance-level methods.
Other examples


