cs224n - Lecture 10. Transformers and Pretraining
Word structure and subword models
- Assumpstions we’ve made:
- Fixed vocab of a number of words, built from the training set.
- All novel words seen at test time are mapped to a single
UNKtoken.
- Finite vocabulary assumptions make even less sense in many languages.
- Many Languages exhibit complex morphology, or word structure.
- The effect is more word types, each occuring fewer times.
- Many Languages exhibit complex morphology, or word structure.
The byte-pair encoding algorithm
Subword modeling in NLP encompasses a wide range of methods for reasoning about structure below the word level. (Parts of words, characters, bytes.)
- The dominant modern paradigm is to learn a vocabulary of parts of words (subword tokens).
- At training and testing time, each word is split into a sequence of known subwords.
Byte-pair encoding is a simple, effective strategy for defining a subword vocabulary.
- Start with a vocabulary containing only characters and an “end-of-word” symbol.
- Using a corpus of text, find the most common adjacent characters “a,b”; add “ab” as a subword.
- Replace instances of the character pair with the new subword; repeat until desired vocab size.
- Ex: starting characters {a, b, $\ldots$, z}. Encoding vocab: {a, $\ldots$, z, $\ldots$, apple, app#, #ly, $\ldots$}
Originally used in NLP for machine translation; now a similar method (WordPiece) is used in pretrained models.
Common words end up being a part of the subword vocabulary, while rarer words are split into (sometimes intuitive, sometimes not) components. In the worst case, words are split into as many subwords as they have characters.

- Problem:
The model has no idea whether it’s dealing with words or subwords.
A rare(or weird) individual single word can be mapped to as many words as its characters, dominates vocabulary.
Motivating word meaning and context
Recall the adage we mentioned at the beginning of the course:
“You shall know a word by the company it keeps” (J. R. Firth 1957: 11)
This quote is a summary of distributional semantics, and motivated word2vec. But:
“… the complete meaning of a word is always contextual, and no study of meaning apart from a complete context can be taken seriously.” (J. R. Firth 1935)
Consider I record the record: the two instances of record mean different things.
Where we were: pretrained word embeddings
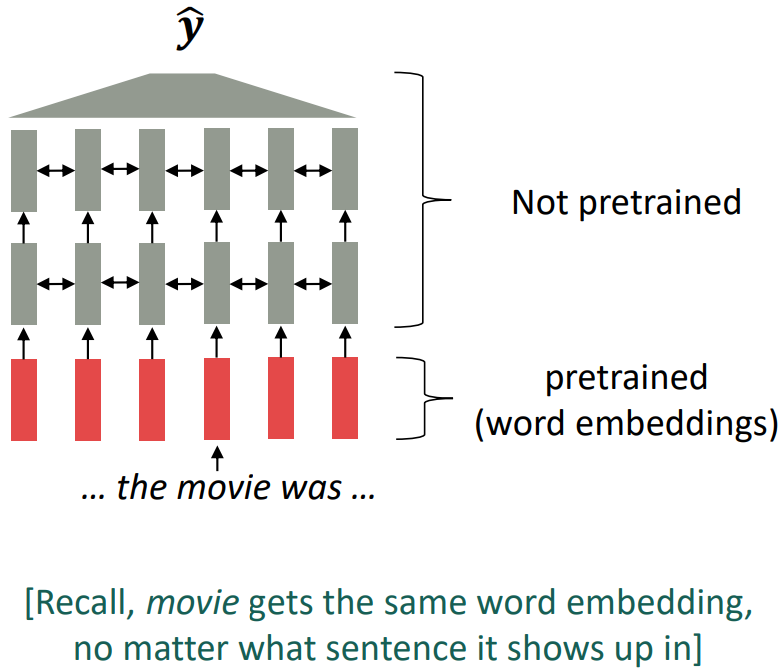 Circa 2017:
Circa 2017:
- Start with pretrained word embeddings (no context)
- Learn how to incorporate context in an LSTM or Transformer while training on the task.
Some issues to think about:
- The training data we have for our downstream task (like question answering) must be sufficient to teach all contextual aspects of language.
- Most of the parameters in our network are randomly initialized!
Where we’re going: pretraining whole models
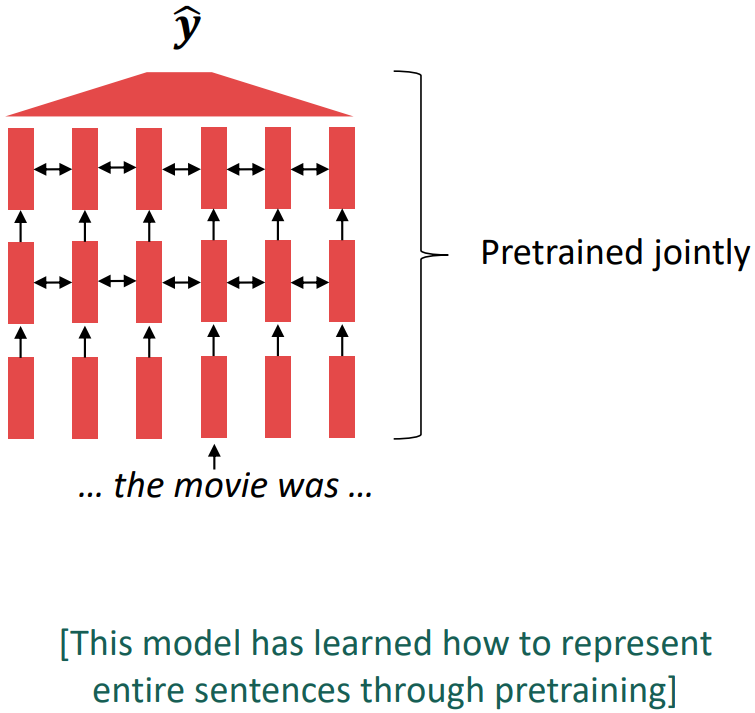 In modern NLP:
In modern NLP:
- All (or almost all) parameters in NLP networks are initialized via pretraining.
- Pretraining methods hide parts of the input from the model, and train the model to reconstruct those parts.
This has been exceptionally effective at building strong:
- representations of language
- parameter initializations for strong NLP models.
- Probability distributions over language that we can sample from
Pretraining through language modeling [Dai and Le, 2015]
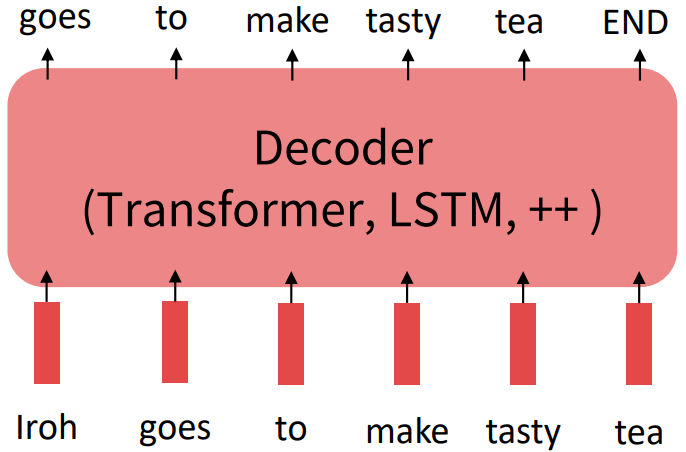 Recall the language modeling task:
Recall the language modeling task:
- Model $p_\theta(w_t \vert w_{1:t-1})$, the probability distribution over words given their past contexts.
- There’s lots of data for this! (In English.)
Pretraining through language modeling:
- Train a neural network to perform language modeling on a large amount of text.
- Save the network parameters.
The Pretraining / Finetuning Paradigm
-
Pretraining can improve NLP applications by serving as parameter initialization
- Step 1: Pretrain (on language modeling)
Lots of text; learn general things - Step 2: Finetune (on your task)
Not many labels; adapt to the task
Stochastic gradient descent and pretrain/finetune
Why should pretraining and finetuning help, from a “training neural nets” perspective?
- Consider, provides parameters $\hat{\theta}$ by approximating \(\text{min}_{\theta} \mathcal{L}_{\text{pretrain}}(\theta)\) (the pretraining loss).
- Then, finetuning approximates \(\text{min}_{\theta } \mathcal{L}_{\text{finetune}}(\theta)\), starting at $\hat{\theta}$ (the finetuning loss).
- The pretraining may matter because stochastic gradient descent sticks (relatively) close to $\hat{\theta}$ during finetuning.
- So, maybe the finetuning local minima near $\hat{\theta}$ tend to generalize well (but still a mystery)
- And/or, maybe the gradients of finetuning loss near $\hat{\theta}$ propagate nicely!
Pretraining for three types of architectures
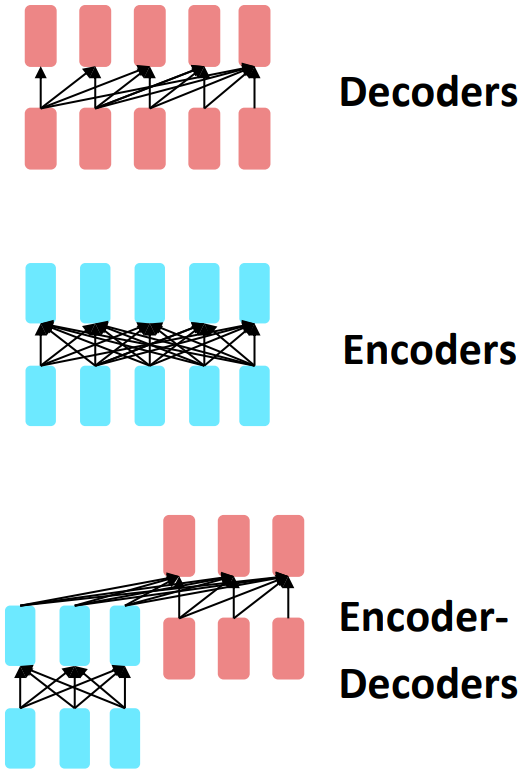
- Language models! What we've seen so far.
- Nice to generate from; can’t condition on future words
- Gets bidirectional context – can condition on future!
- Wait, how do we pretrain them?
(if you try pretrain it as a language model, the loss will be 0 because you feed the future information)
- Good parts of decoders and encoders?
- What’s the best way to pretrain them?
Pretraining Decoders (1)
- When pretraining a language model, we try to approximate the probability of a word given all of its previous words; $p_\theta(w_t \vert w_{1:t-1})$. When using language model pretrained decoders, we can ignore that they were trained to model $p$.
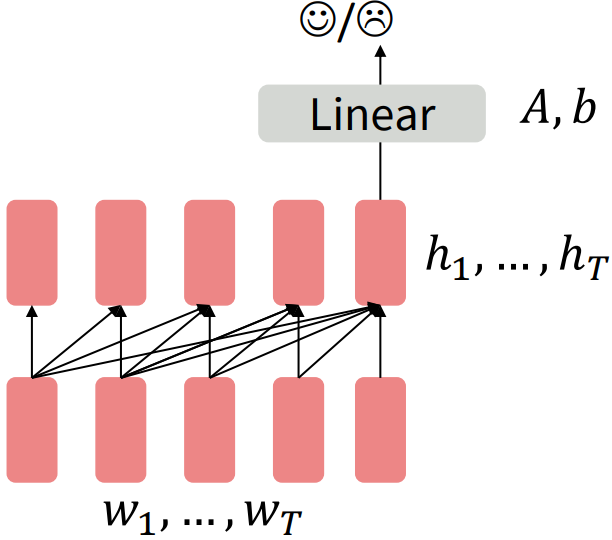 - We can finetune them by training a classifier on the last word’s hidden state.
- We can finetune them by training a classifier on the last word’s hidden state.
$$\begin{align*}
h_1, \ldots, h_T &= \text{Decoder}(w_1, \ldots, w_T) && (w \text{is a subword}) \\
& y \sim Ah_t + b
\end{align*}$$
- Where $A, b$ are randomly initialized (not pretrained) and specified by the downstream task.
- Gradients backpropagate through the wholde network, not just the linear layer.
Pretraining Decoders (2)
- It’s natural to pretrain decoders as language models and then use them as generators, finetuning their $p_\theta(w_t \vert w_{1:t-1})$
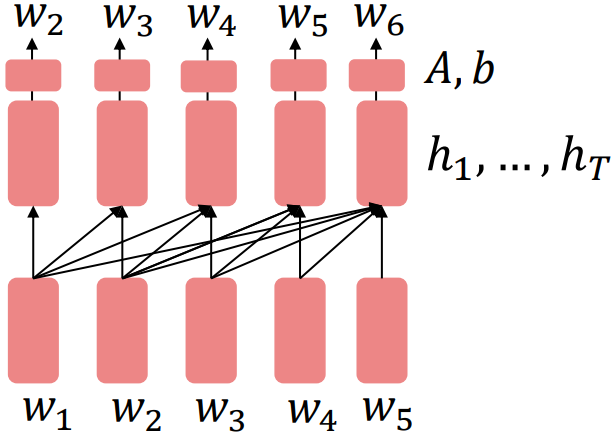 This is helpful in tasks where the output is a sequence with a vocabulary like that at pretraining time.
This is helpful in tasks where the output is a sequence with a vocabulary like that at pretraining time.
- Dialogue (context=dialogue history)
- Summarization (context=document)
$$\begin{align*}
h_1, \ldots, h_T &= \text{Decoder}(w_1, \ldots, w_T) \\
& w_t \sim Ah_{t-1} + b
\end{align*}$$
- Where $A, b$ were pretrained in the language model
Generative Pretrained Transformer (GPT) [Radford et al., 2018]
- 2018’s GPT was a big success in pretraining a decoder!
- Transformer decoder with 12 layers.
- 768-dimensional hidden states, 3072-dimensional feed-forward hidden layers.
- Byte-pair encoding with 40,000 merges. (relatively small vocab)
- Trained on BooksCorpus: over 7000 unique books.
- Contains long spans of contiguous text, for learning long-distance dependencies.
- The acronym “GPT” never showed up in the original paper; it could stand for “Generative PreTraining” or “Generative Pretrained Transformer”
- How do we format inputs to our decoder for finetuning tasks?
- Evaluate on Natural Language Inference: Label pairs of sentences as entailing/contradictory/neutral
e.g., sentence entailment in
Premise: The man is in the doorway
Hyphothesis: The person is near the door - input format (roughly):
[START]The man is in the doorway[DELIM]The person is near the door[EXTRACT]
The linear classifier is applied to the representation of the[EXTRACT]token.
- Evaluate on Natural Language Inference: Label pairs of sentences as entailing/contradictory/neutral
- The amount of task-specific human effort is very low!
Increasingly convinsing generations (GPT2) [Radford et al., 2018]
- We mentioned how pretrained decoders can be used in their capacities as language models.
GPT-2, a larger version of GPT trained on more data, was shown to produce relatively convincing samples of natural language.

Pretraining Encoders: what pretraining objective to use?
Encoders get bidirectional context, so we can’t do language modeling!
$\rightarrow$ Masked Language Modeling
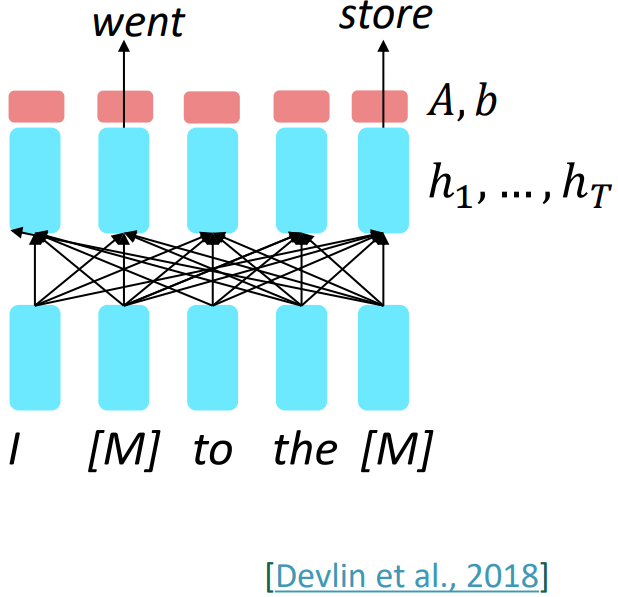 - Idea: replace some fraction of words in the input with a speical `[MASK]` token; predict these words.
- Idea: replace some fraction of words in the input with a speical `[MASK]` token; predict these words.
$$\begin{align*}
h_1, \ldots, h_T &= \text{Encoder}(w_1, \ldots, w_T) \\
& y_i \sim Aw_i + b
\end{align*}$$
- Only add loss terms from words that are "masked out". If $\hat{x}$ is the masked version of $x$, we're learning $p_{\theta}(x\vert \hat{x})$.
-
Devlin et al., 2018 proposed the “Masked LM” objective and released the weights of a pretrained Transformer, a model they labeled BERT.
-
Some more details about Masked LM for BERT:
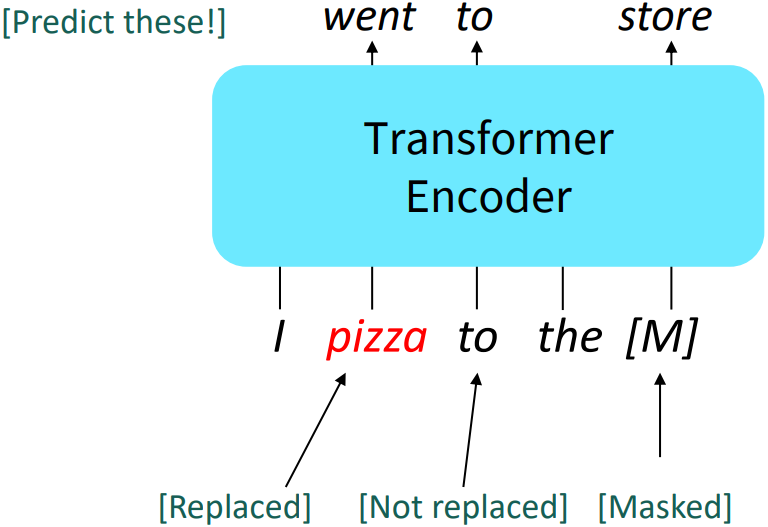 Predict a random 15% of (sub)word tokens.
Predict a random 15% of (sub)word tokens.
- Replace input word with [MASK] 80% of the time
- Replace input word with a random token 10% of the time
- Leave input word unchanged 10% of the time (but still predict it!)
(So we have three loss terms for example sentence)
- Why?: Doesn’t let the model get complacent and not build strong representations of non-masked words.
(No masks are seen at fine-tuning time!)
BERT: Bidirectional Encoder Representations from Transformers
- The pretraining input to BERT was two separate contiguous chunks of text:
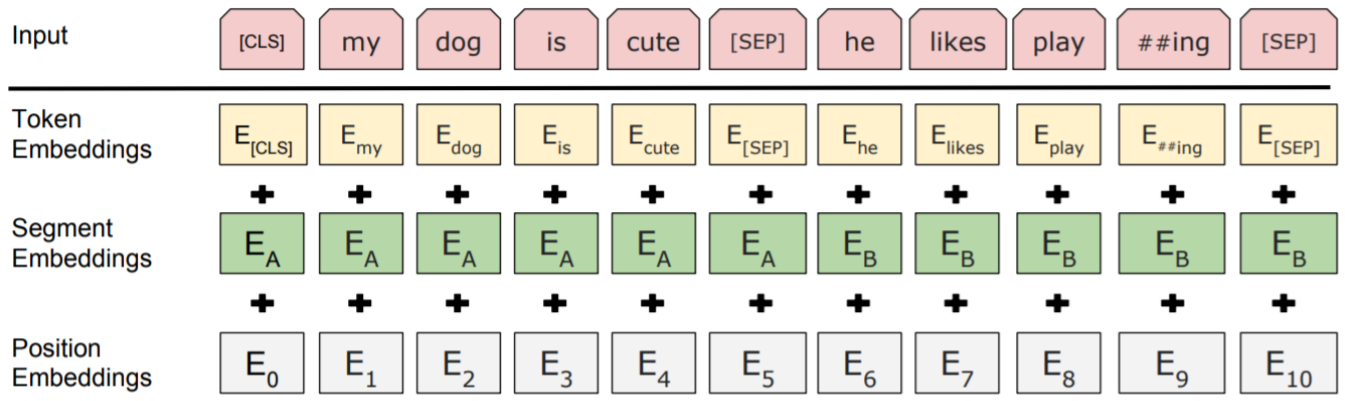
- Two chunks of text:
To better pretrain for objectives for downstream applications like QA, where you have two different pieces of text; sometimes actual chunk of text that directly follows the first chunk, or sometimes randomly sampled unrelated.
$\rightarrow$ BERT was trained to predict whether one chunk follows the other or is randomly sampled.- Later work has argued this “next sentence prediction” is not necessary.
- Details about BERT
- Two models were released:
- BERT-base: 12 layers, 768-dim hidden states, 12 attention heads, 110 million params.
- BERT-large: 24 layers, 1024-dim hidden states, 16 attention heads, 340 million params.
- Trained on:
- BooksCorpus (800 million words)
- English Wikipedia (2,500 million words)
- Pretraining is expensive and impractical on a single GPU.
- BERT was pretrained with 64 TPU chips for a total of 4 days.
- Finetuning is practical and common on a single GPU
- “Pretrain once, finetune many times.”
- Two models were released:
- BERT was massively popular and hugely versatile; finetuning BERT led to new state-of-the-art results on a broad range of tasks.
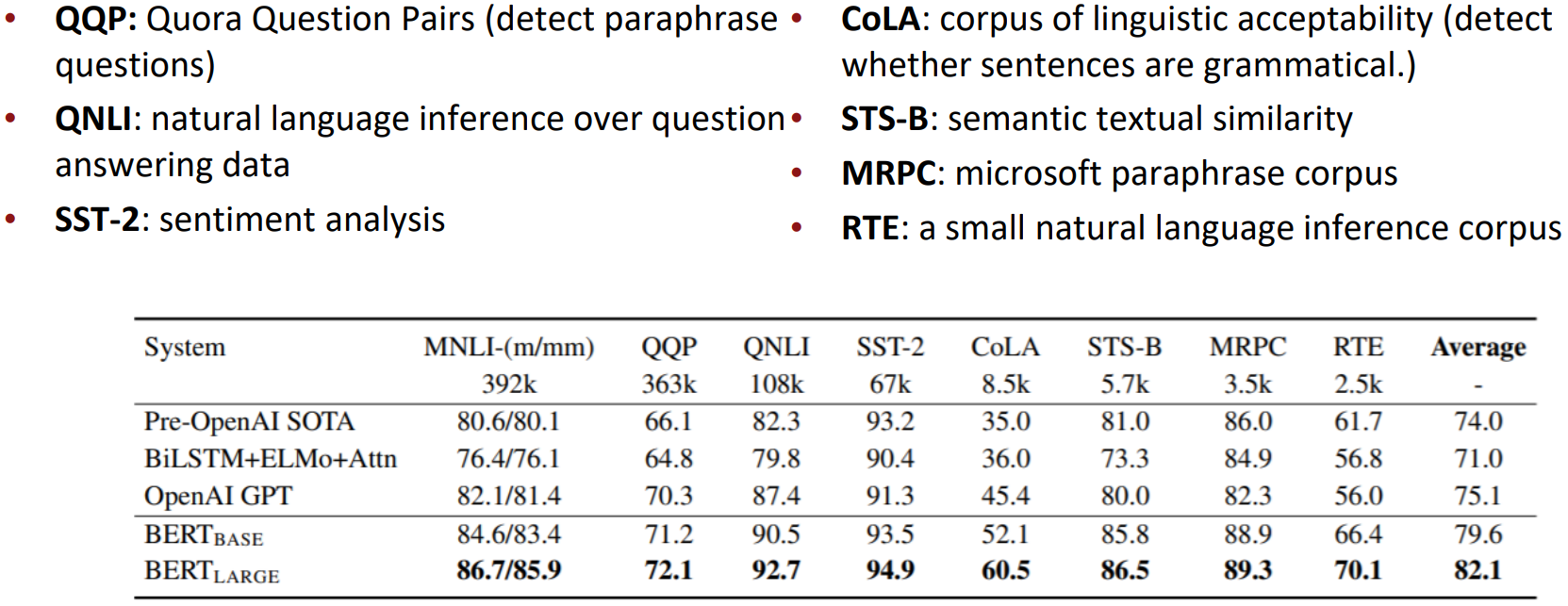
Limitations of pretrained encoders
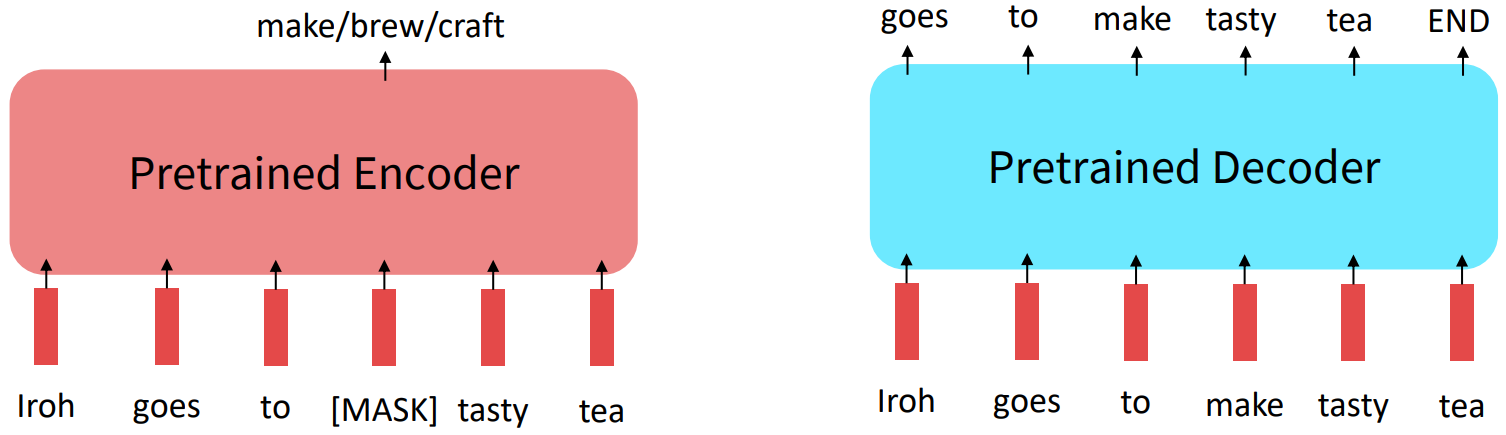
If your task involves generating sequences, consider using a pretrained decoder; BERT and other pretrained encoders don’t naturally lead to nice autoregressive (1-word-at-a-time) generation methods.
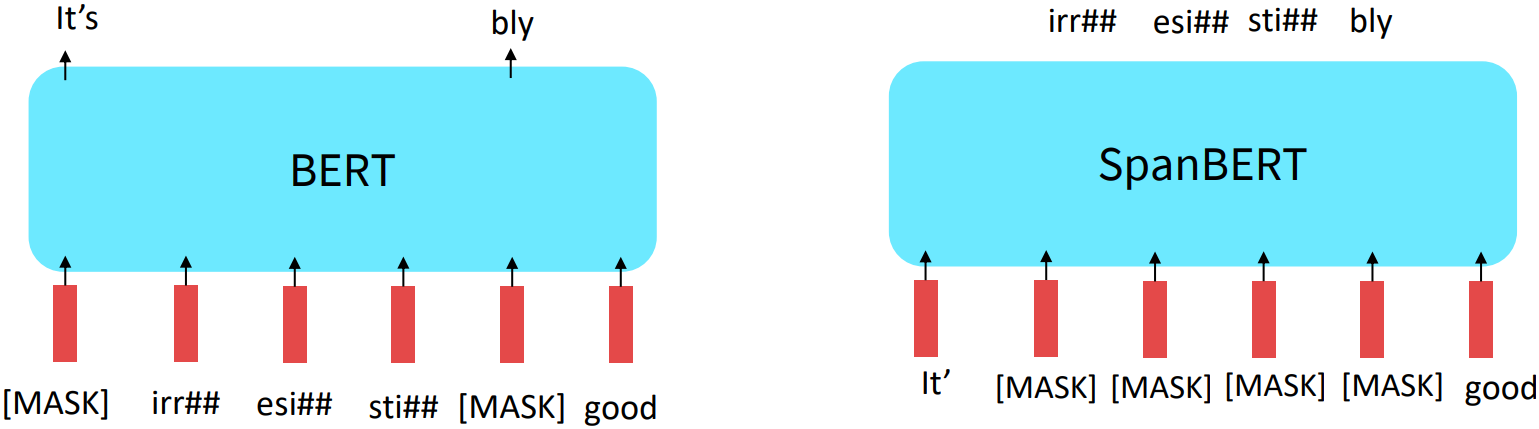
Extensions of BERT
- Among a lot of BERT variants, some generally accepted improvements to the BERT pretraining formula:
- RoBERTa: mainly just train BERT for longer and remove next sentence prediction [Liu et al., 2019]
more compute, more data can improve pretraining even when not changing the underlying Transformer encoder. - SpanBERT: masking contiguous spans of words makes a harder, more useful pretraining task [Joshi et al., 2020]
- RoBERTa: mainly just train BERT for longer and remove next sentence prediction [Liu et al., 2019]
Pretraining Encoder-Decoders: what pretraining objective to use?
- For encoder-decoders, we could do something like language modeling, but where a prefix of every input is provided to the encoder and is not predicted.
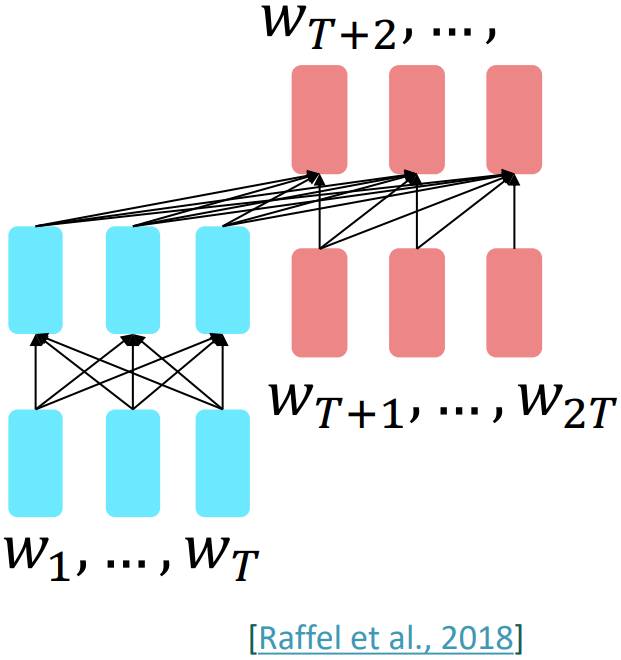 $$\begin{align*}
h_1, \ldots, h_T &= \text{Encoder}(w_1, \ldots, w_T) \\
h_{T+1}, \ldots, h_{2T} &= \text{Decoder}(w_1, \ldots, w_T, h_1, \ldots, h_T \\
& y_i \sim Aw_i + b, && i > T
\end{align*}$$
$$\begin{align*}
h_1, \ldots, h_T &= \text{Encoder}(w_1, \ldots, w_T) \\
h_{T+1}, \ldots, h_{2T} &= \text{Decoder}(w_1, \ldots, w_T, h_1, \ldots, h_T \\
& y_i \sim Aw_i + b, && i > T
\end{align*}$$
The encoder portion benefits from bidirectional context; the decoder portion is used to train the whole model through language modeling.
- What Raffel et al., 2018 found to work best was span corruption. Their model: T5.
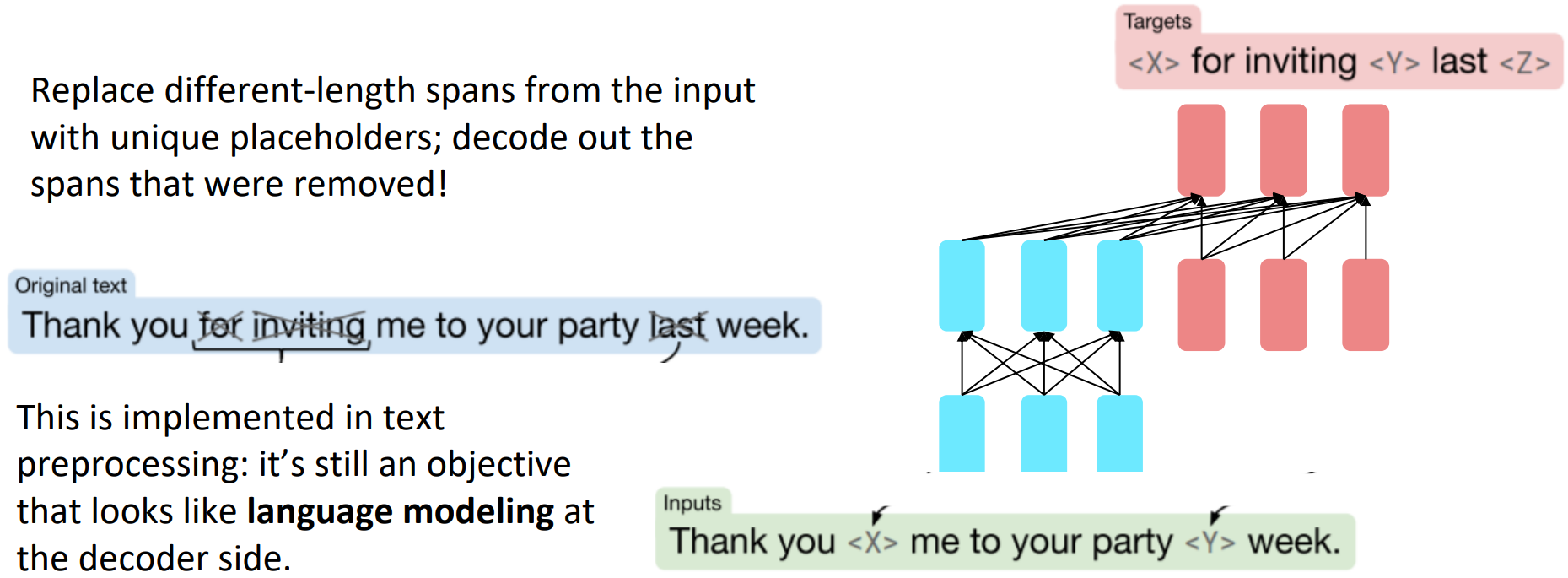
-
Unlike BERT, this model doesn’t specify the length of missing token
<X>. -
Raffel et al., 2018 found encoder-decoders to work better than decoders for their tasks, and span corruption (denoising) to work better than language modeling.
-
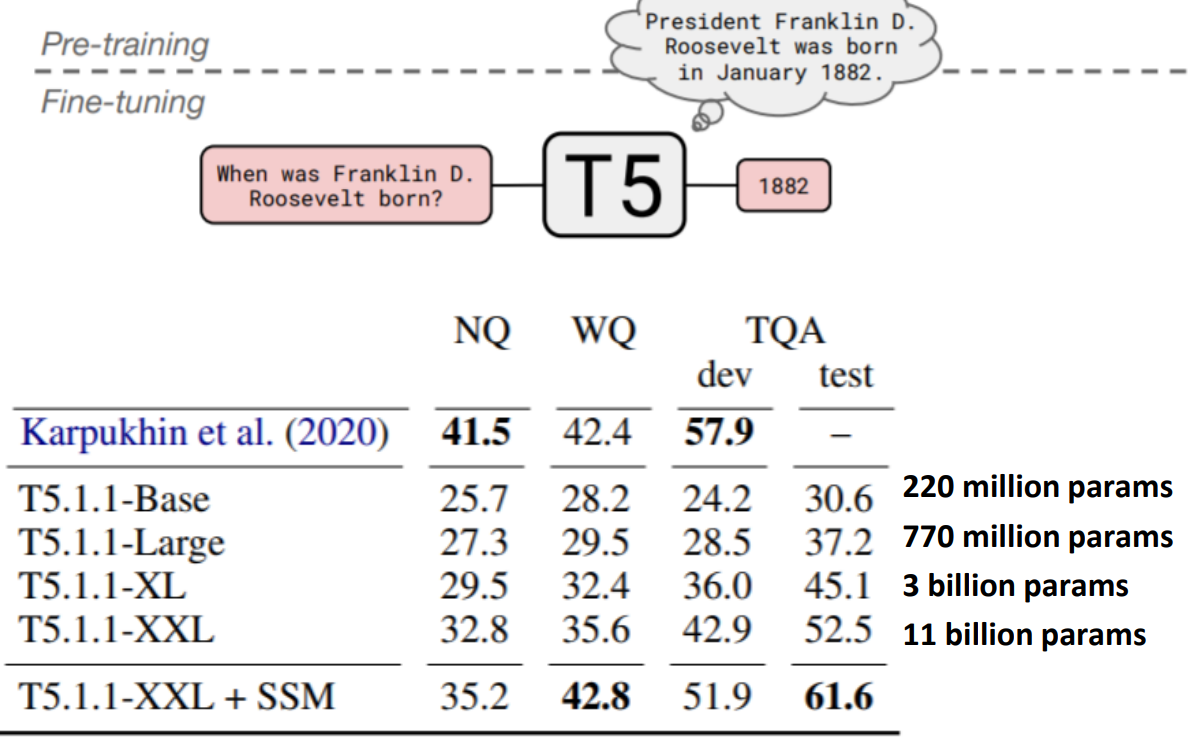
A fascinating property of T5:
it can be finetuned to answer a wide range of questions, retrieving knowledge from its parameters.- NQ: Natural Questions
- WQ: WebQuestions
- TQA: Trivia QA
All “open-domain” versions
What kinds of things does pretraining learn?
There’s increasing evidence that pretrained models learn a wide variety of things about the statistical properties of language. Taking our examples from the start of class:
- Stanford University is located in ______, California. [Trivia]
- I put ___ fork down on the table. [syntax]
- The woman walked across the street, checking for traffic over ___ shoulder. [coreference]
- I went to the ocean to see the fish, turtles, seals, and _____. [lexical semantics/topic]
- Overall, the value I got from the two hours watching it was the sum total of the popcorn and the drink. The movie was ___. [sentiment]
- Iroh went into the kitchen to make some tea. Standing next to Iroh, Zuko pondered his destiny. Zuko left the __. [some reasoning – this is harder]
- I was thinking about the sequence that goes 1, 1, 2, 3, 5, 8, 13, 21, ____ [some basic arithmetic; they don’t learn the Fibonnaci sequence]
- Models also learn – and can exacerbate racism, sexism, all manner of bad biases.
- More on all this in the interpretability lecture!
GPT-3, In-context learning, and very large models
- So far, we’ve interacted with pretrained models in two ways:
- Sample from the distributions they define (maybe providing a prompt)
- Fine-tune them on a task we care about, and take their predictions.
- Very large language models seem to perform some kind of learning without gradient steps simply from examples you provide within their contexts.
The in-context examples seem to specify the task to be performed, and the conditional distribution mocks performing the task to a certain extent.- Input (prefix within a single Transformer decoder context):
thanks -> merci
hello -> bonjour
mint -> menthe
otter -> ? - Output (conditional generations):
loutre…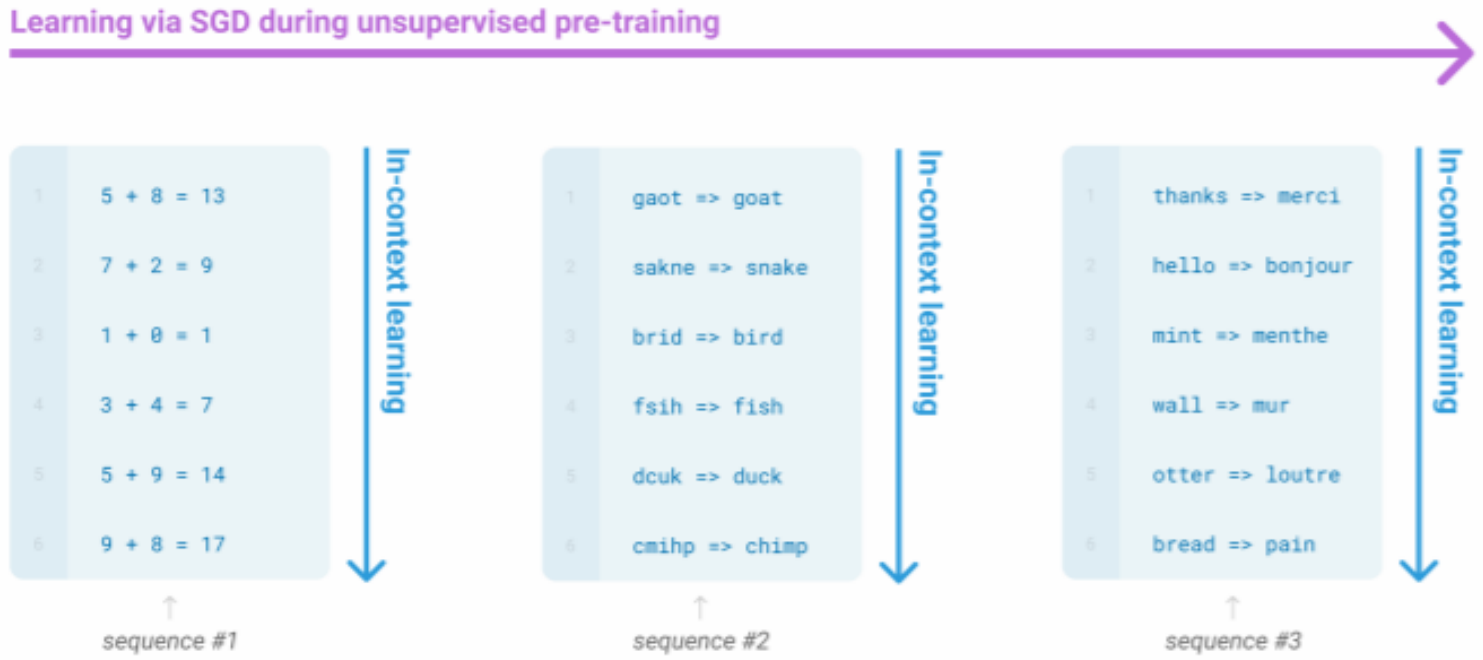
- Input (prefix within a single Transformer decoder context):
-
GPT-3 is the canonical example of this. The largest T5 model had 11 billion parameters but GPT-3 has 175 billion parameters.
- Remarks
These models are still not well-understood.
“Small” models like BERT have become general tools in a wide range of settings.