cs231n - Lecture 15. Detection and Segmentation
Computer Vision Tasks
- Image Classification: No spatial extent
- Semantic Segmentation: No objects, just pixels
- Object Detection/ Instance Segmentation: Multiple objects
Semantic Segmentation
- Paired training data:
For each training image, each pixel is labeled with a semantic category. - At test time, classify each pixel of a new image.
- Problem:
Classifying with only single pixel does not include context information. - Idea:
- Sliding Window
Extract patch from full image, classify center pixel with CNN.
$\color{red}{(-)}$ Very inefficient, not reusing shared features between overlapping patches. - Convolution
Encode the entire image with conv net, and do semantic segmentation on top.
$\color{red}{(-)}$ CNN architectures often change the spatial sizes, but semantic segmentation requires the output size to be same as input size. - Fully Convolutional
Design a network with only convolutional layers without downsampling operators
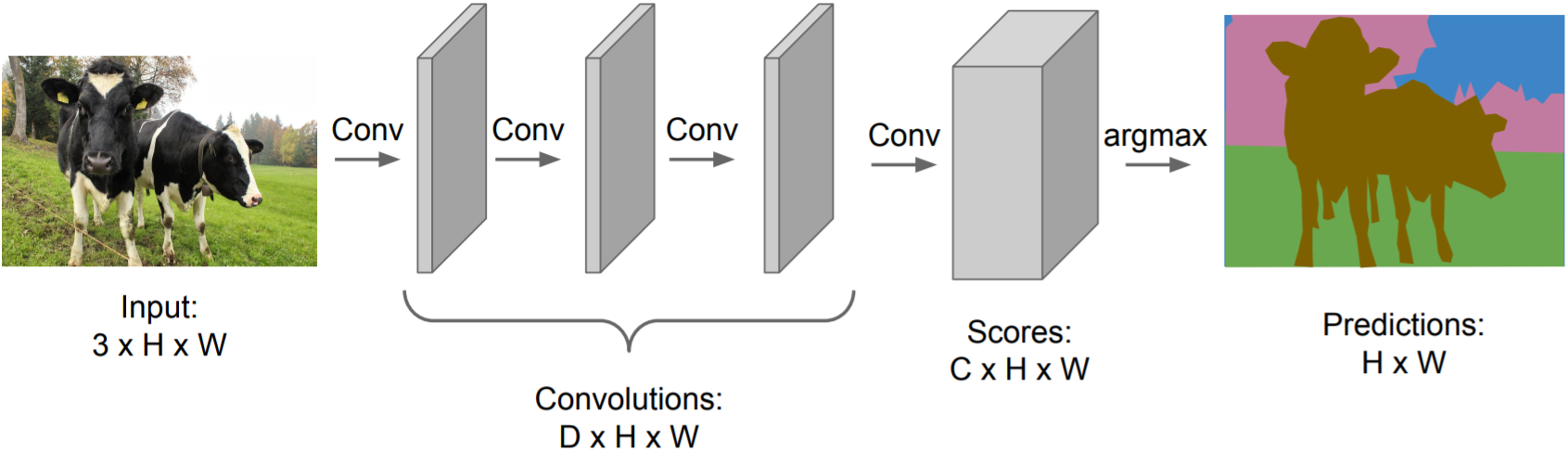
$\color{red}{(-)}$ convolutions at original image resolution is very expensive
$\rightarrow$ Design convolutional network with downsampling and upsampling
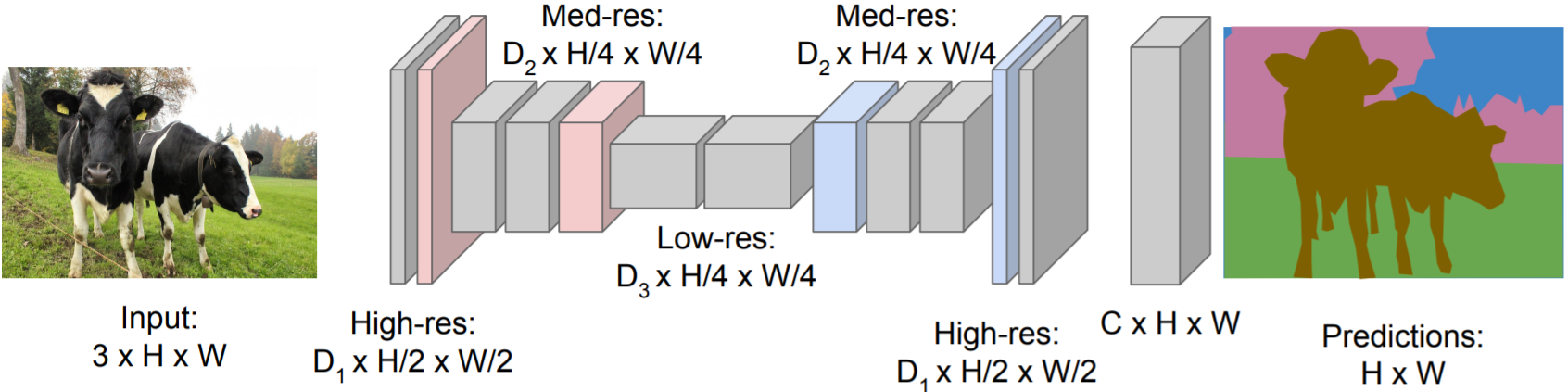
- Sliding Window
- Downsampling: Pooling, strided convolution
-
In-Network Upsampling: Unpooling, strided transpose convolution
-
Unpooling:
Nearest Neighbor: copy-paste to extended region
“Bed of Nails”: no positional argument, pad with zeros -
Max Unpooling: use positions from poolying layer ahead, pad with zeros
-
Learnable Downsampling: Strided convolution
Output is a dot product between filter and input
Stride gives ratio between movement in input and output -
Learnable Upsampling: Transposed convolution
Input gives weight for filter
Output contains copies of the filter weighted by the input, summing at where at overlaps in the output

- Summary
Label each pixel in the image with a category label
Don’t differentiate instances, only care about pixels
Object Detection
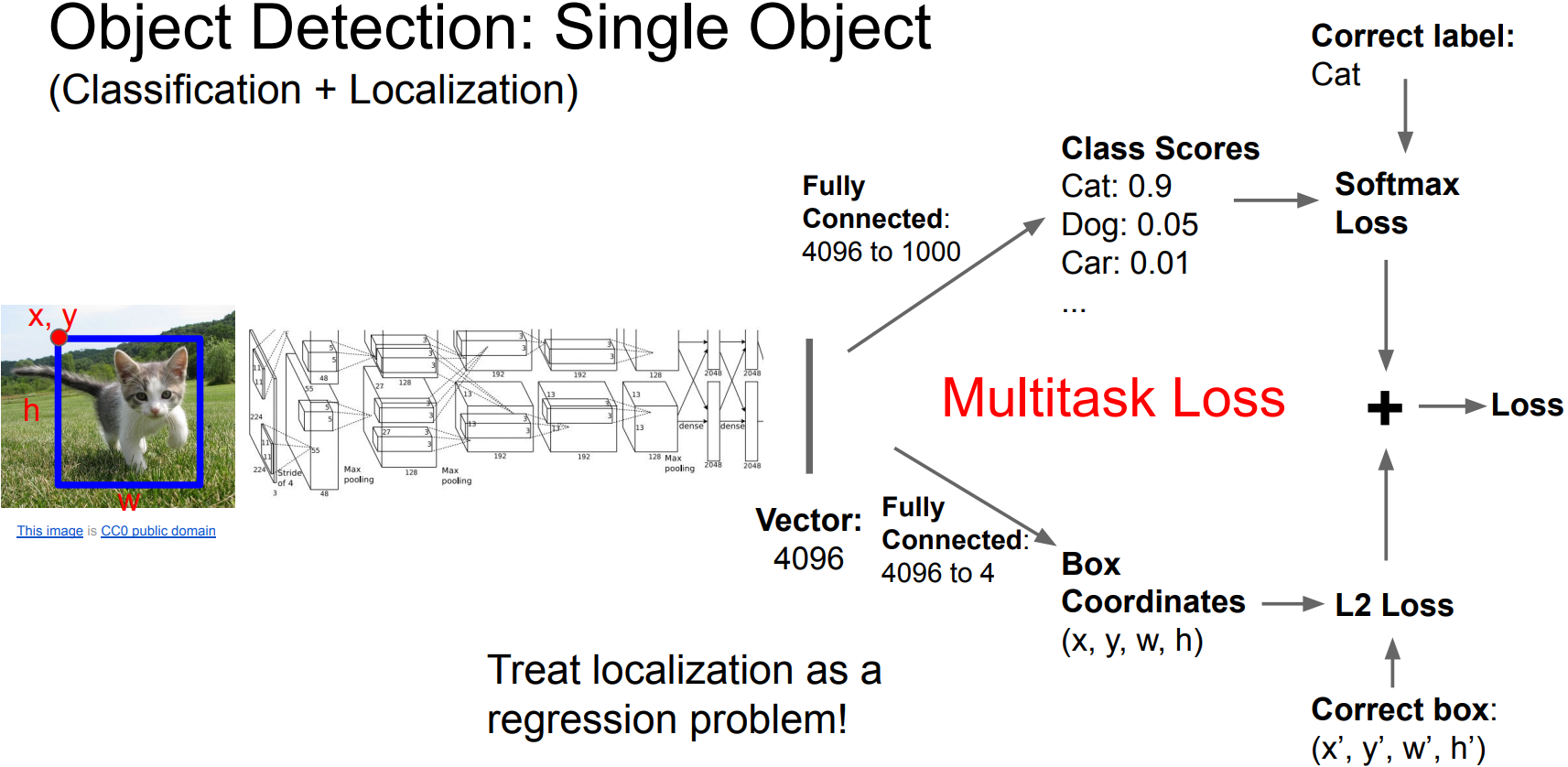
- Multiple Objects:
Each image needs a different number of outputs;
$\rightarrow$ Apply a CNN to many different crops of the image, CNN classifies each crop as object or background.
$\color{red}{(-)}$ Need to apply CNN to huge number of locations, scales, and aspect ratios, very computationally expensive.
R-CNN
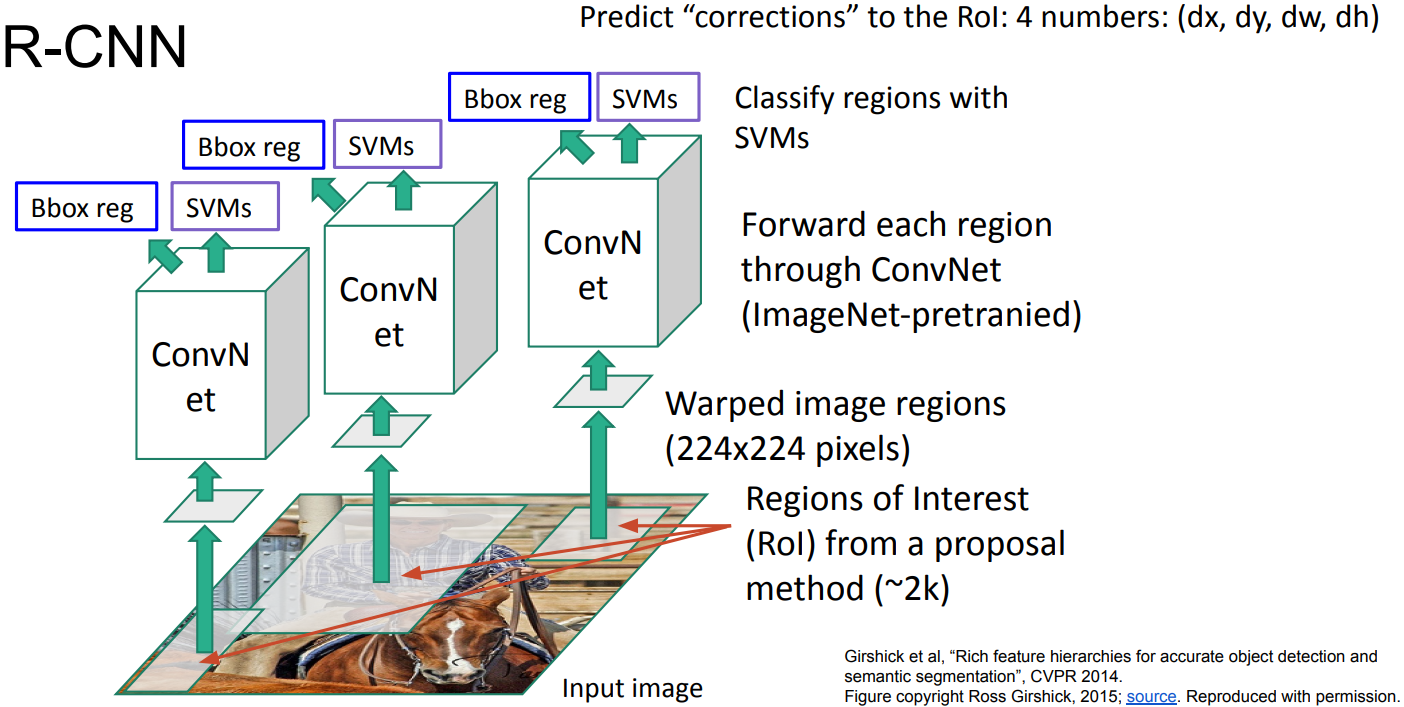
-
Girshick et al, “Rich feature hierarchies for accurate object detection and semantic segmentation”, CVPR 2014
- 2-stage Detector: Region Proposal + Region Classification
- Image as input
- Crop bounding boxes with Selective Search
Warp into same size pixels for CNN model - Input Warped images into CNN
- Run classification on each
- Algorithm:
- Region Proposals: Selective Search
Find “blobby” image regions that are likely to contain objects.
Relatively fast to run; e.g. Selective Search gives 2000 region proposals in a few seconds on CPU. - CNN:
For a pre-trained CNN architecture, change the number of classes on the last classification layer(detection classes N + background 1), fine-tune with dataset for Object Detection. From the region proposal input, outputs a fixed-length feature vector. - SVM: Category-Specific Linear SVMs
Positive: ground-truth boxes
Negative: IoU under 0.3
Scores each feature vector for classes, classifies whether each one is positive/negative(is_object). - Non-Maximum Suppression: with concept of IoU
Intersection over Union; area of intersection divided by area of union
If there are two boxes with IoU over 0.5, consider them proposed on the same object, leave one with the highest score. - Bounding Box Regression: adjust boxes from Selective Search
- Algorithm:
Assume a bounding box $P^i = (P_x^i, P_y^i, P_w^i, P_h^i)$,
Ground-truth box $G = (G_x, G_y, G_w, G_h)$.
Define a function $d$, mapping $P$ close to $G$;
\(\hat{G}_x = P_w d_x(P) + P_x\)
\(\hat{G}_y = P_h d_y(P) + P_y\)
\(\hat{G}_w = P_w \mbox{exp}(d_w(P))\)
\(\hat{G}_h = P_h \mbox{exp}(d_h(P))\)
where $d_{\star}(P) = w_{\star}^T \phi_5(P)$, is modeled as a linear function(learnable weight vector w) of thePOOL5features of proposal P($\phi_5(P)$). We learn $w_{\star}$ by optimizing the regularized least squares objective(Ridge regression)
Learnable parameters on: 2, 3, 5
- Algorithm:
- Region Proposals: Selective Search
- Summary:
Score: 53.7% on Pascal VOC 2010
Problem:
1. Low Performance; Warping images into 224x224 size for AlexNet
2. Slow; Using all candidates from Selective Search
3. Not GPU-optimized; Using Selective Search and SVM
4. No Back Propagation; Not sharing computations
Fast R-CNN
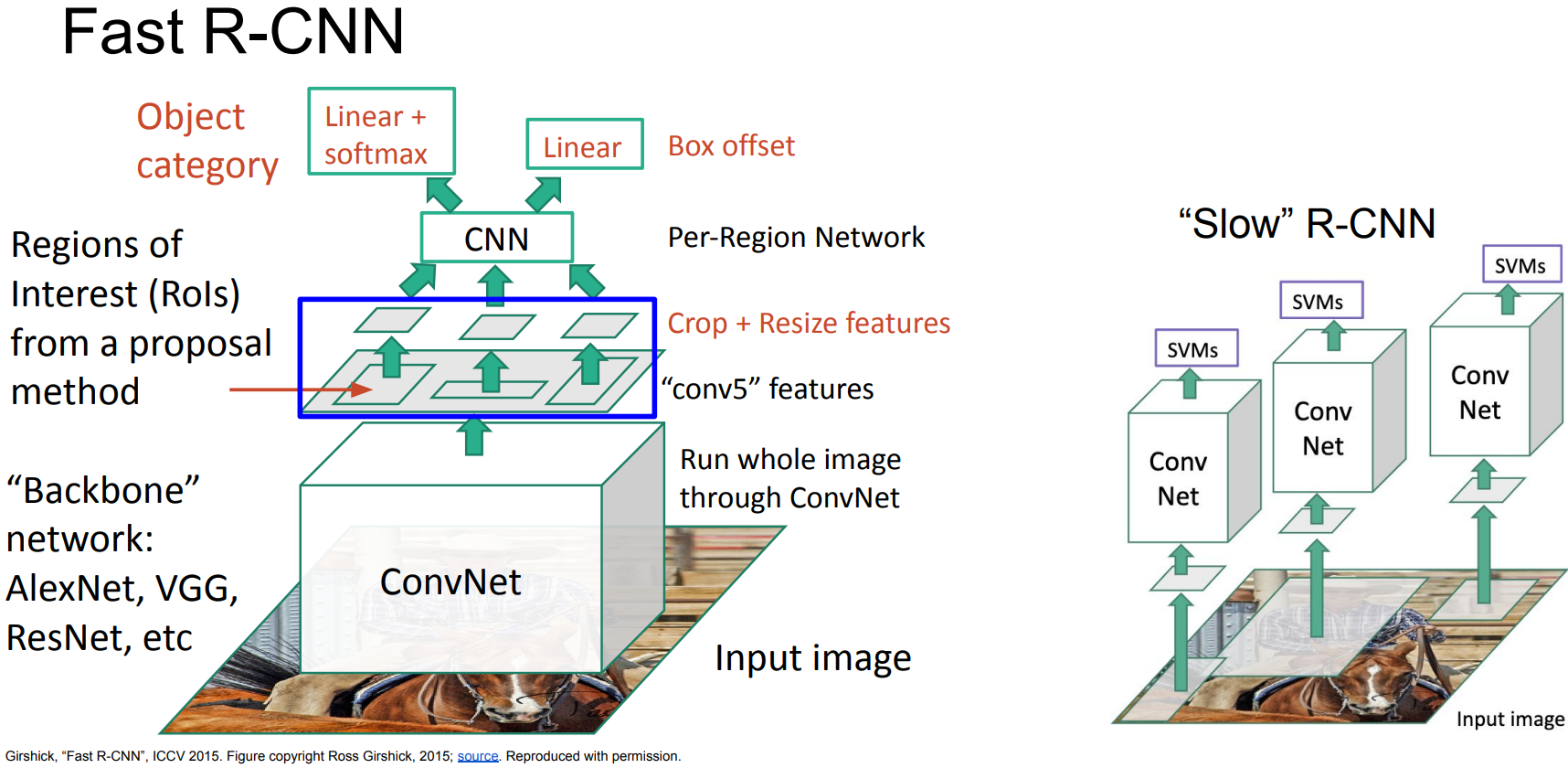
-
Girshick, “Fast R-CNN”, ICCV 2015
-
idea:
Pass the image through convnet before cropping. Crop the conv feature instead. - Algorithm:
- Pass the full image through pre-trained CNN and extract feature maps.
- Get RoIs from a proposal method(Selective Search) and crop by RoI Pooling, get fixed size feature vectors.
- With RoI feature vectors, pass some fully connected layers and split into two branches.
- 1) pass softmax and classify the class of RoI. no SVM used. 2) Run bounding box regression.
- Cropping Features: RoI Pool
- Project RoI proposals(on input image) onto CNN image features.
- Divide into subregions.
- Run pooling(Max-pool) within each subregion.
$\rightarrow$ Region features always be the same size regardless of input region size
Faster R-CNN
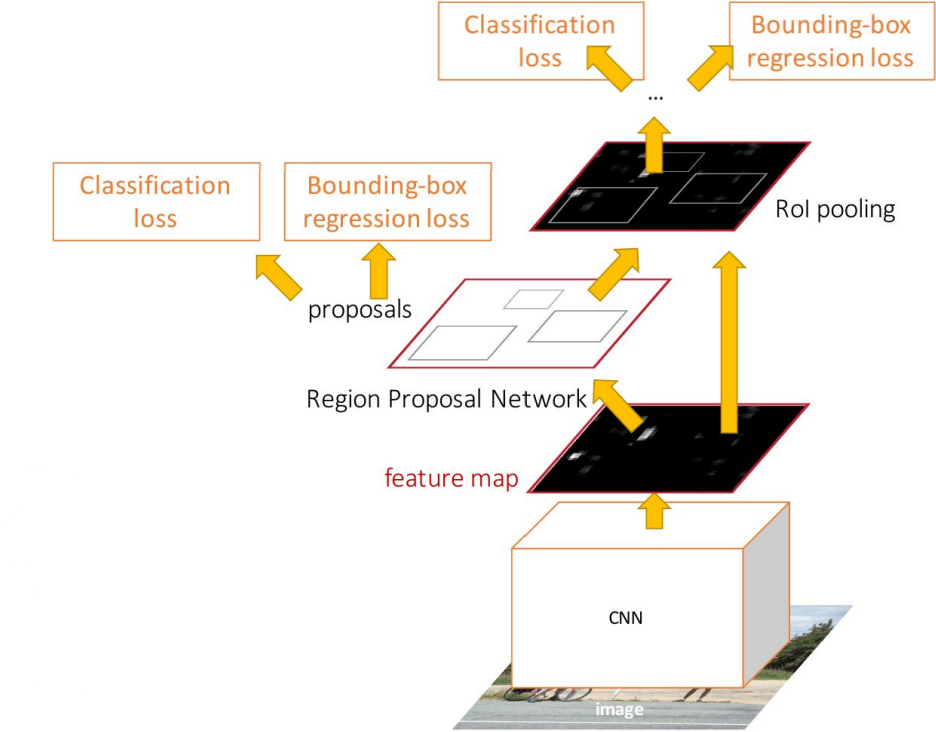
-
Ren et al, “Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks”, NIPS 2015
-
idea:
Fast R-CNN is not GPU-optimized; runtime dominated by region proposals.
By inserting Region Proposal Network(RPN), implemented end-to-end architecture. - Algorithm:
- Pass the full image through pre-trained CNN and extract feature maps.
- RPN:
For K different anchor boxes of different size and scale at each point in the feature map, predict whether it contains an object(binary classification), and also predict a corrections from the anchor to the ground-truth box(regress 4 numbers per pixel).
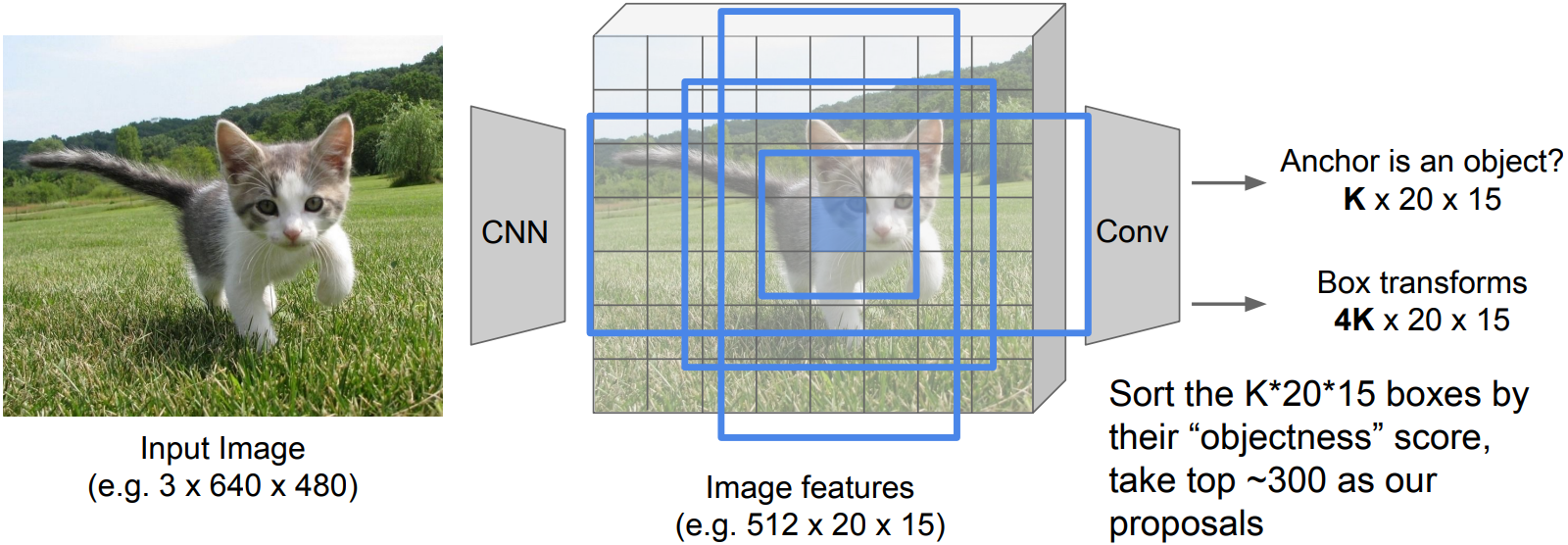
- Jointly train with 4 losses:
1) RPN classify object / not object
2) RPN regress box coordinates
3) Final classification score (object classes)
4) Final box coordinates
- Glossing over many details:
- Ignore overlapping proposals with non-max suppression
- How are anchors determined?
- How do we sample positive / negative samples for training the RPN?
- How to parameterize bounding box regression?
- Two-stage object detector:
- First stage: Run once per image
- Backbone network
- Region proposal network(RPN)
- Second stage: Run once per region
- Crop features: RoI pool/ align
- Predict object class
- Prediction bbox offset
- First stage: Run once per image
Single-Stage Object Detectors: YOLO / SSD / RetinaNet
- Algorithm:
- Divide input imgae into grid
- Image a set of base boxes centered at each grid cell
- Within each grid cell:
- Regress from each of the B base boxes to a final box with 5 numbers(dx, dy, dh, dw, confidence)
- Predict scores for each of C classes(including background as a class)
- Looks a lot like RPN, but category-specific

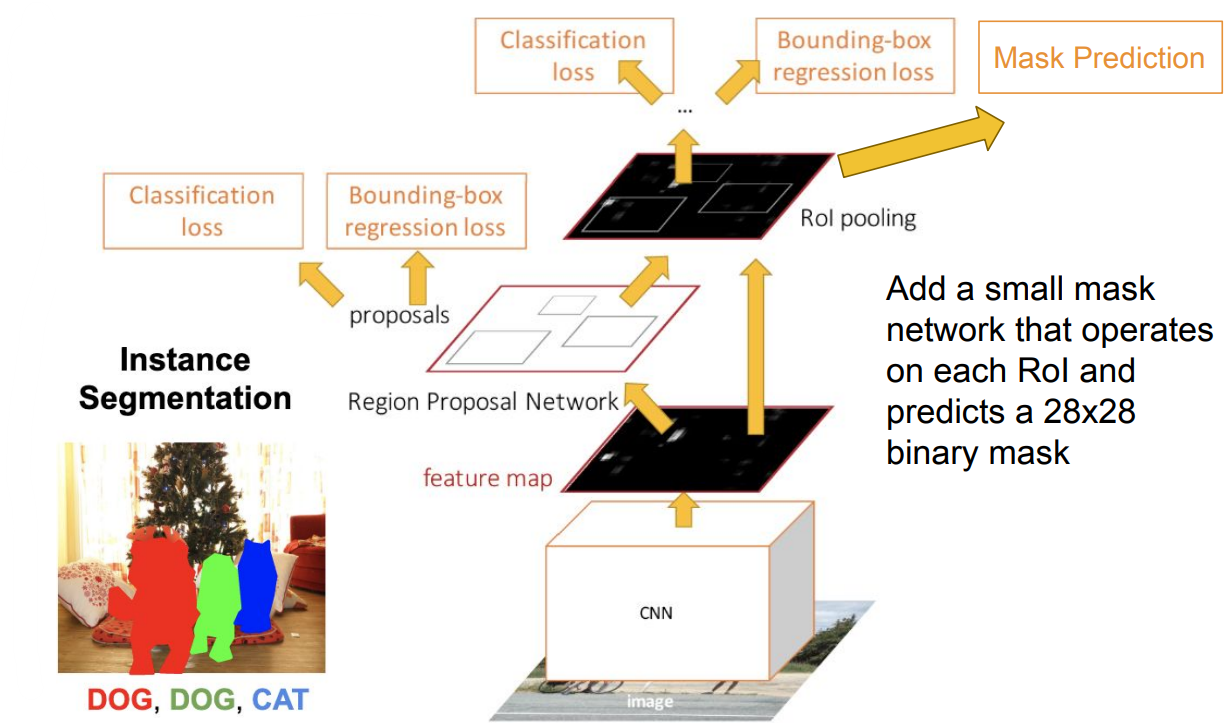
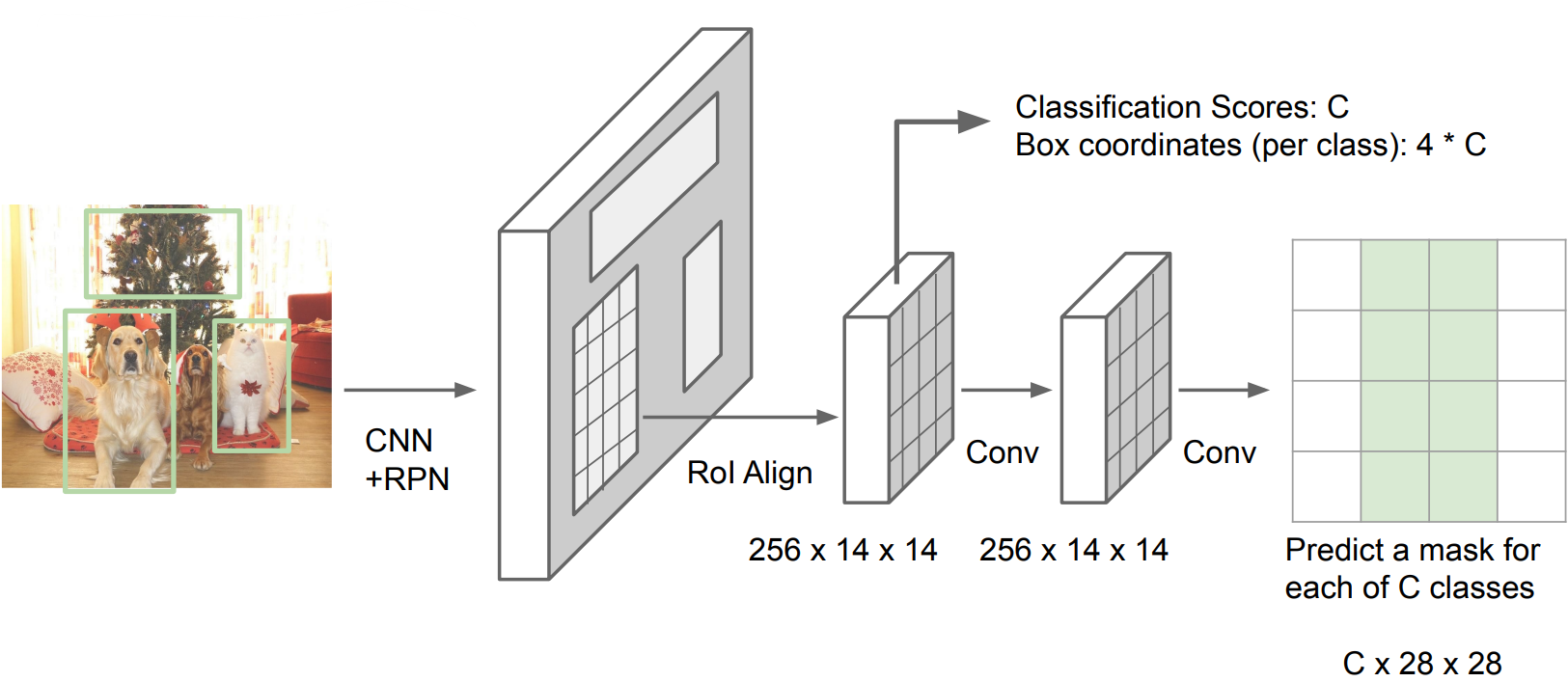
Instance Segmentation: Mask R-CNN
- He et al, “Mask R-CNN”, ICCV 2017



Open Source Frameworks
TensorFlow Detection API
Detectron2(Pytorch)
Beyond 2D Object Detection
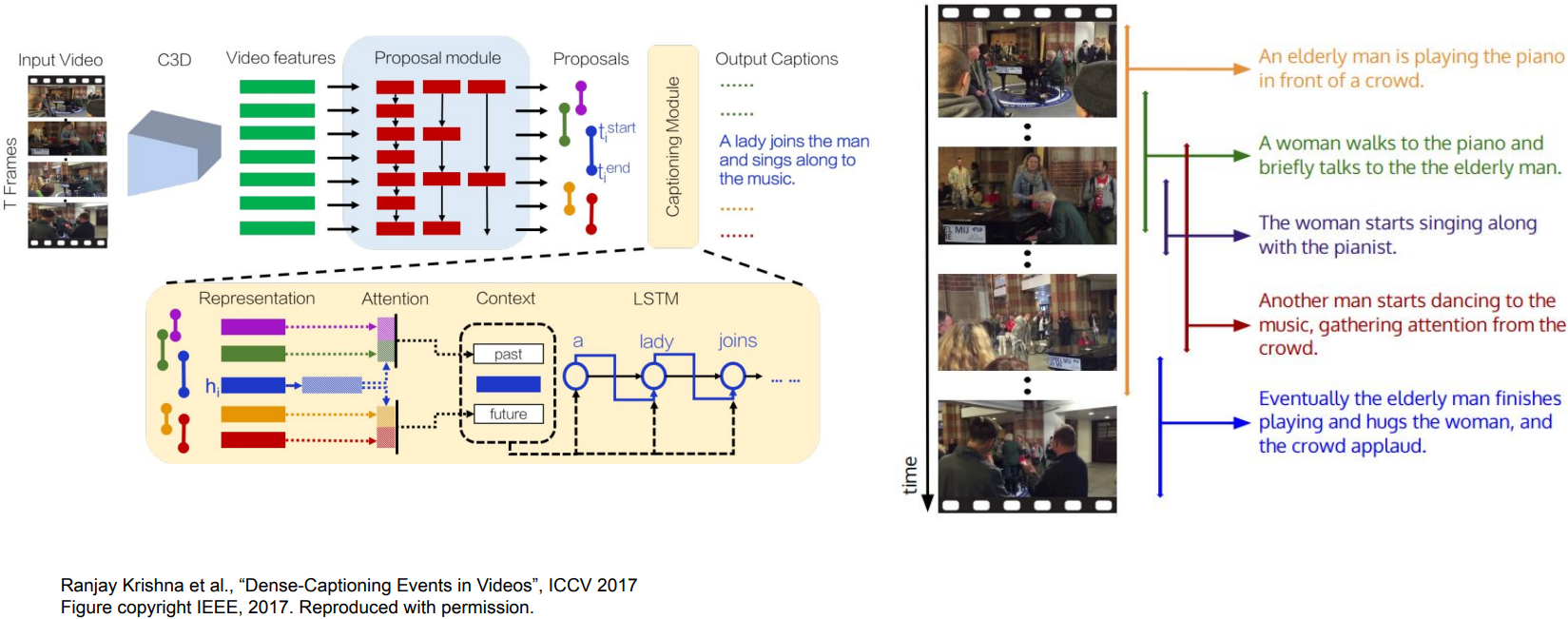
Object Detection + Captioning: Dense Captioning
Dense Video Captioning: timestep “T”
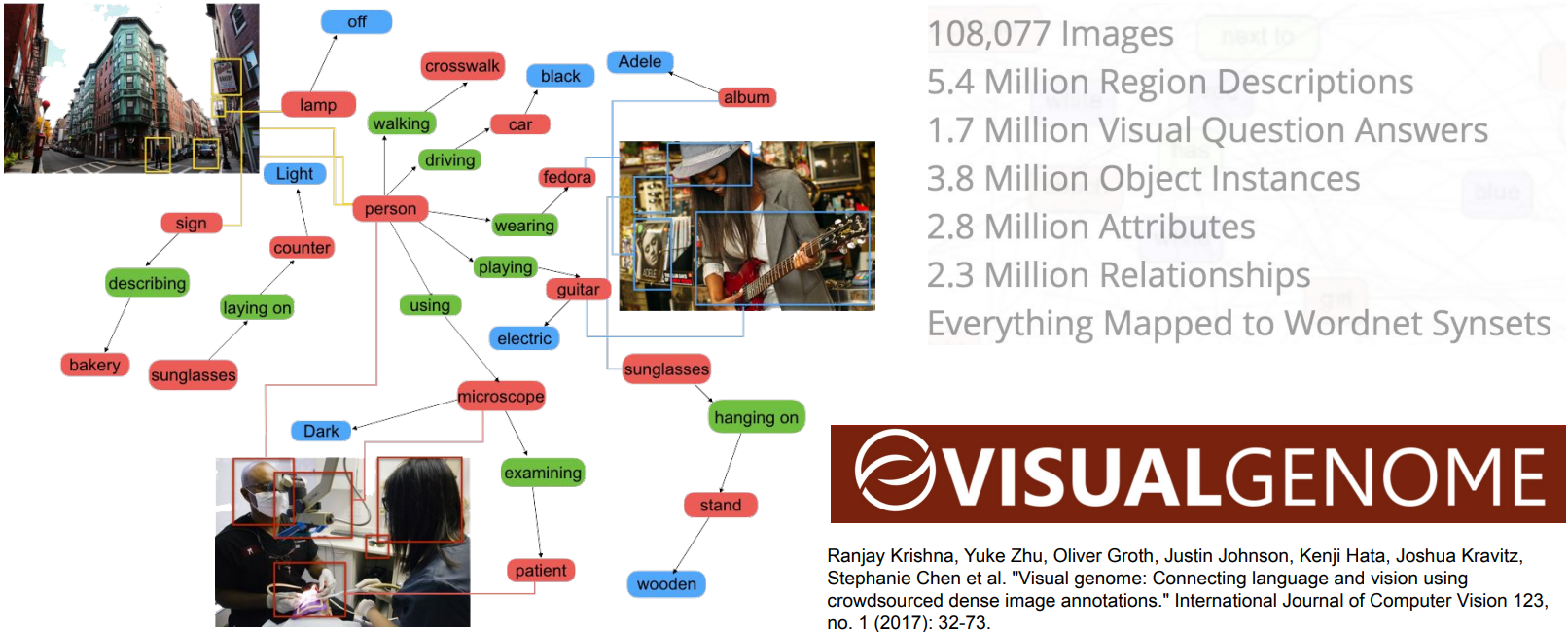
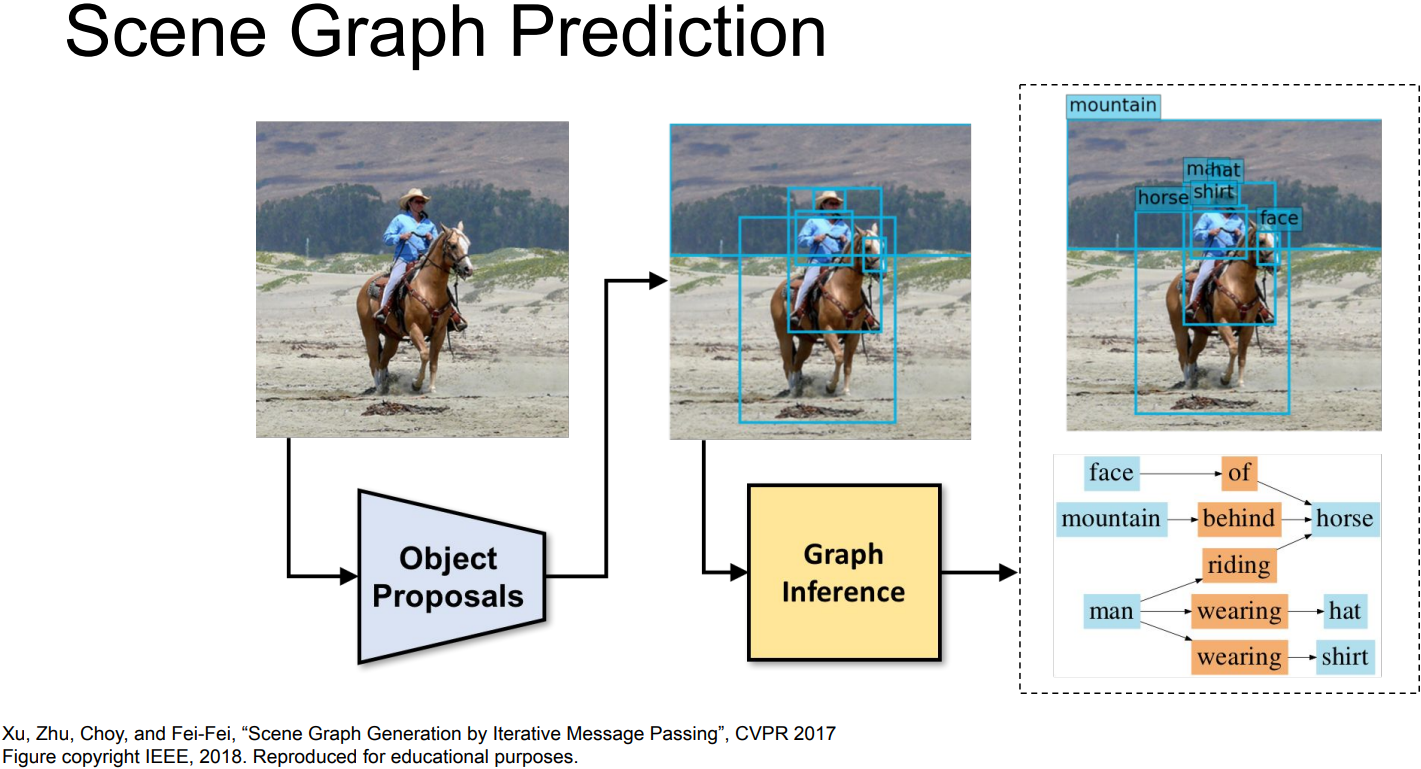
Objects + Relationships: Scene Graphs
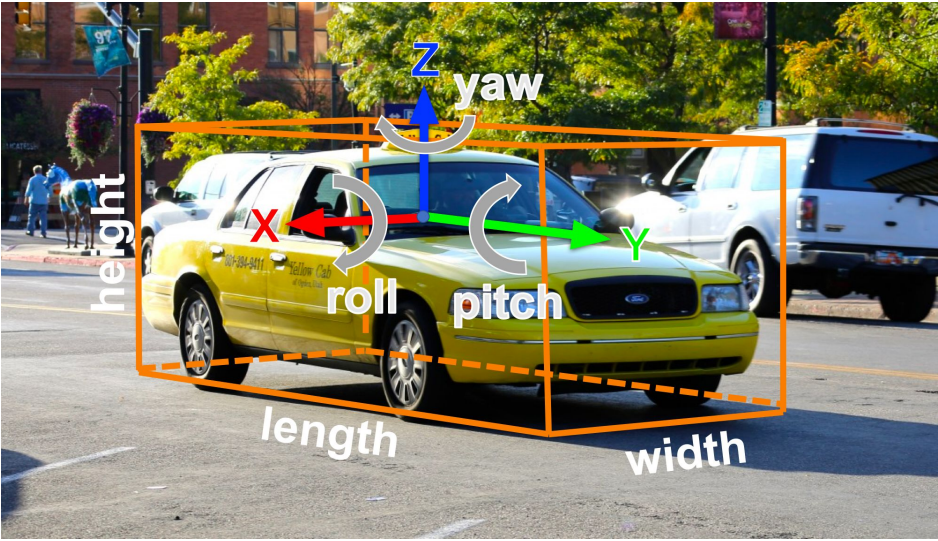
3D Object Detection
-
2D bounding box: (x, y, w, h)
$\rightarrow$ 3D oriented bounding box: (x, y, z, w, h, l, r, p, y)
$\rightarrow$ Simplified bbox: no roll & pitch -
Simple Camera Model:
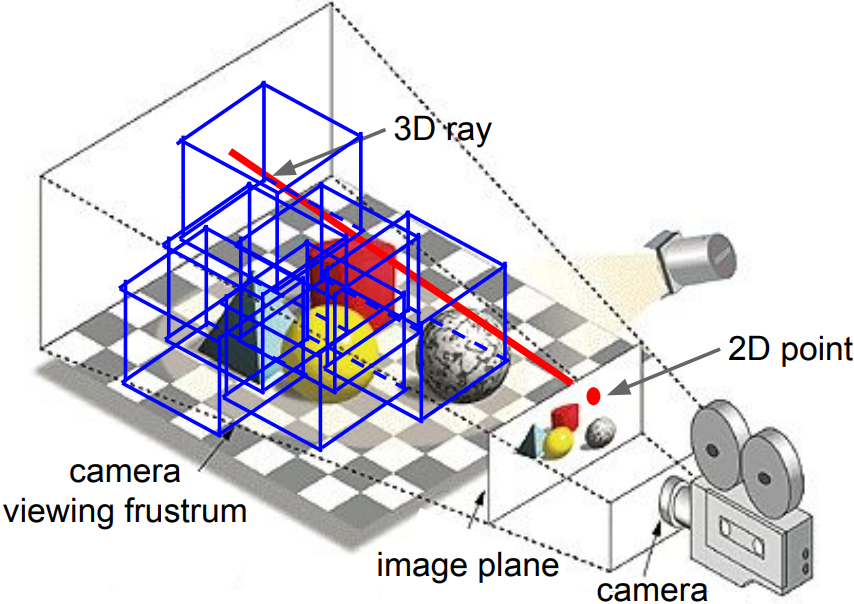
A point on the image plane corresponds to a ray in the 3D space
A 2D bounding box on an image is a frustrum in the 3D space
Localize an object in 3D: The object can be anywhere in the camera viewing frustrum - Monocular Camera:
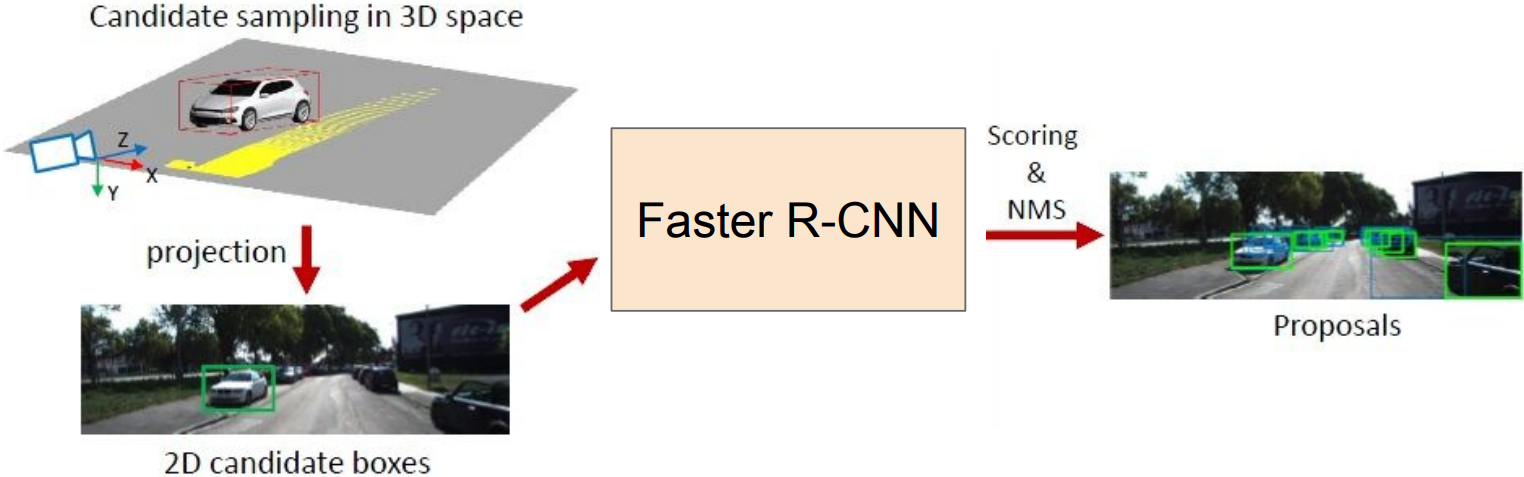
- Same idea as Faster RCNN, but proposals are in 3D
- 3D bounding box proposal, regress 3D box parameters + class score
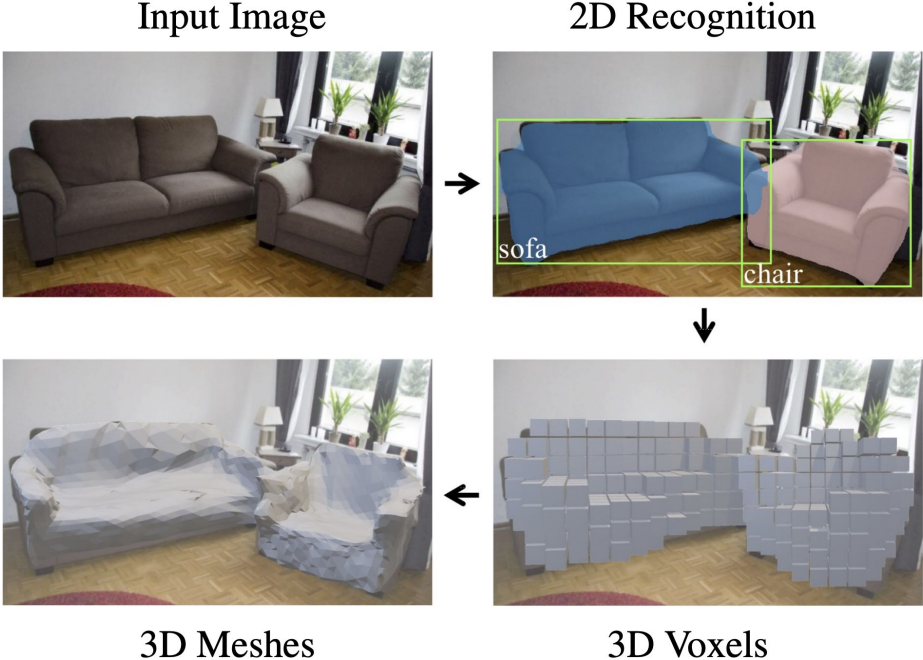
- 3D Shape Prediction: Mesh R-CNN