cs231n - Lecture 9. CNN Architectures
Review
-
LeCun et al., 1998
$5\times 5$ Conv filters applied at stride 1
$2\times 2$ Subsampling (Pooling) layers applied at stride 2
i.e. architecture is[CONV-POOL-CONV-POOL-FC-FC] -
Stride: Downsample output activations
Padding: Preserve input spatial dimensions in output activations
Filter: Each conv filter outputs a “slice” in the activation
Case Studies
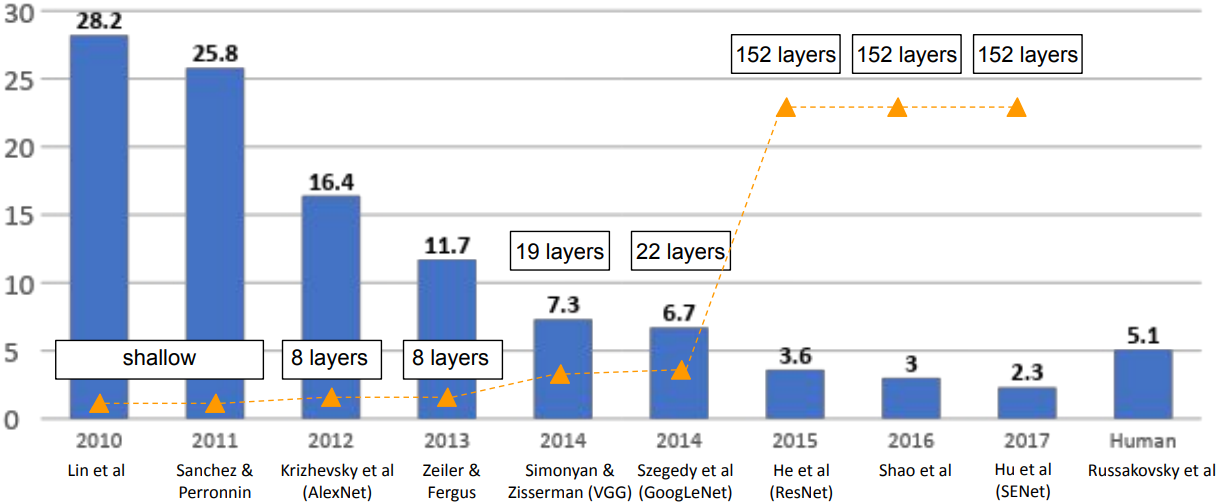
AlexNet: First CNN-based winner
- Architecture:
[CONV1-MAXPOOL1-NORM1-CONV2-MAXPOOL2-NORM2-CONV3-CONV4-CONV5-MaxPOOL3-FC6-FC7-FC8]- Input: $227\times 227\times 3$ images
- First layer(CONV1):
96 $11\times 11$ filters applied at stride 4, pad 0
Output volume: $W’ = (W-F+2P)/S + 1 \rightarrow$ $55\times 55\times 96$
Parameters: $(11* 11* 3 +1)* 96 =$ 36K - Second layer(POOL1):
$3\times 3\times$ filters applied at stride 2
Output volume: $27\times 27\times 96$
Parameters: 0
$\vdots$ - CONV2($27\times 27\times 256$):
256 $5\times 5$ filters applied at stride 1, pad 2 - MAX POOL2($13\times 13\times 256):
$3\times 3\times$ filters applied at stride 2 - CONV3($13\times 13\times 384$):
384 $3\times 3$ filters applied at stride 1, pad 1 - CONV4($13\times 13\times 384$):
384 $3\times 3$ filters applied at stride 1, pad 1 - CONV5($13\times 13\times 256$):
256 $3\times 3$ filters applied at stride 1, pad 1 - MAX POOL3($6\times 6\times 256$):
$3\times 3\times$ filters applied at stride 2 - FC6(4096): 4096 neurons
- FC7(4096): 4096 neurons
- FC8(1000): 1000 neurons (class scores)
- Historical note:
- Network spread across 2 GPUs, half the neurons (feature maps) on each GPU.
- CONV1, CONV2, CONV4, CONV5: Connections only with feature maps on same GPU
- CONV3, FC6, FC7, FC8: Connections with all feature maps in preceding layer, communication across GPUs
- Details/Retrospectives:
- Krizhevsky et al. 2012
- first use of ReLU
- used Norm layers (not common anymore)
- heavy data augmentation
- dropout 0.5
- batch size 128
- SGD Momentum 0.9
- Learning rate 1e-2, reduced by 10 manually when val accuracy plateaus
- L2 weight decay 5e-4
- 7 CNN ensemble: 18.2% $\rightarrow$ 15.4%
ZFNet: Improved hyperparameters over AlexNet
- AlexNet but:
- CONV1: change from ($11\times 11$ stride 4) to ($7\times 7$ stride 2)
- CONV3,4,5: instead of 384, 384, 256 filters use 512, 1024, 512
- ImageNet top 5 error: 16.4% -> 11.7%
- Zeiler and Fergus, 2013
VGGNet: Deeper Networks
- Small filters, Deeper networks
- 8 layers (AlexNet) $\rightarrow$ 16 - 19 layers (VGG16Net)
- Only $3\times 3$ CONV stride 1, pad 1 and $2\times 2$ MAX POOL with stride 2
- 11.7% top 5 error(ZFNet) $\rightarrow$ 7.3% top 5 error in ILSVRC’14
-
Why use smaller filters?
:Stack of three $3\times 3$ conv (stride 1) layers has same effective receptive field as one $7\times 7$ conv layer, but with deeper, more non-linearities and fewer parameters
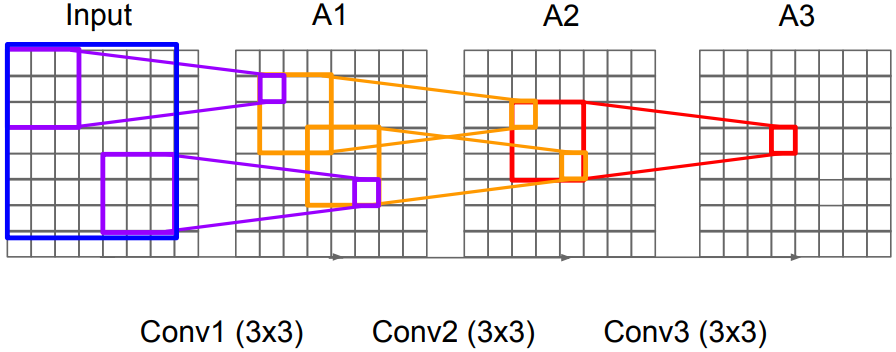
-
TOTAL memory:
24M * 4 bytes ~= 96MB/ image (for a forward pass)
TOTAL params:138Mparameters
Most memory is in early CONV, Most params are in late FC - Details:
- Simonyan and Zisserman, 2014
- ILSVRC’14 2nd in classification, 1st in localization
- Similar training procedure as Krizhevsky 2012
- No Local Response Normalisation (LRN)
- Use VGG16 or VGG19 (VGG19 only slightly better, more memory)
- Use ensembles for best results
- FC7 features generalize well to other tasks
GoogLeNet
- Inception module:
- design a good local network topology(network within a network) and then stack these modules on top of each other
- Apply parallel filter operations on the input from previous layer: Multiple receptive field sizes for convolution(1x1, 3x3, 5x5), Pooling(3x3)
- Concatenate all filter outputs together channel-wise
- “Bottlenect” layers to reduce computational complexity of inception:
- use 1x1 conv to reduce feature channel size; alternatively, interpret it as applying the same FC layer on each input pixel
- preserves spatial dimensions, reduces depth
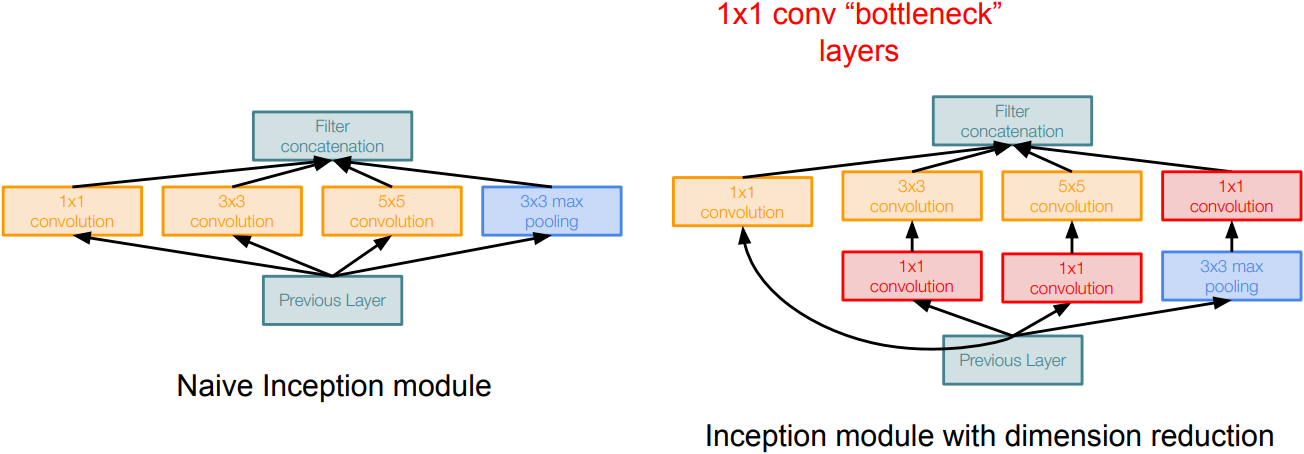
- Full GoogLeNet Architecture:
- Stem Network:
[Conv-POOL-2x CONV-POOL] - Stack Inception modules: with dimension reduction on top of each other
- Classifier output:
[(H*W*c)-Avg POOL-(1*1*c)-FC-Softmax]
Global average pooling layer before final FC layer, avoids expensive FC layers - Auxiliary classification layers:
[AvgPool-1x1 Conv-FC-FC-Softmax]
to inject additional gradient at lower layers
- Stem Network:
- Details:
- Deeper networks, with computational efficiency
- ILSVRC’14 classification winner (6.7% top 5 error)
- 22 layers
- Only 5 million parameters(12x less than AlexNet, 27x less than VGG-16)
- Efficient “Inception” module
- No FC layers
ResNet
-
From 2015, “Revolution of Depth”; more than 100 layers
- Stacking deeper layers on a “plain” convolutional neural network results in lower both test and training error. The deeper model performs worse, but it’s not caused by overfitting.
- Fact: Deep models have more representation power (more parameters) than shallower models.
- Hypothesis: the problem is an optimization problem, deeper models are harder to optimize
- Solution: copying the learned layers from the shallower model and setting additional layers to identity mapping.
- “Residual block”:
- Use network layers to fit a residual mapping instead of directly trying to fit a desired underlying mapping
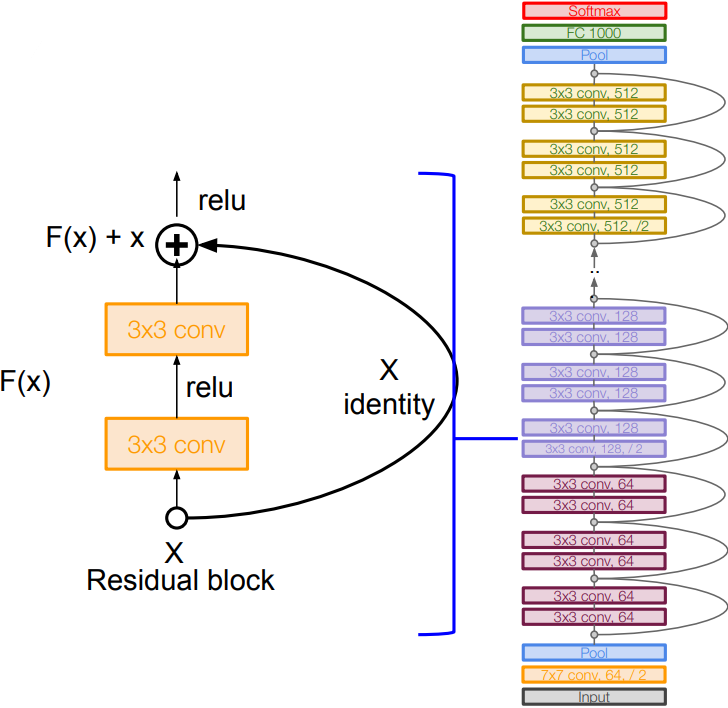
- Full ResNet Architecture:
- Stack residual blocks
- Every residual block has two $3\times 3$ conv layers
- Periodically, double number of filters and downsample spatially using stride 2 (/2 in each dimension). Reduce the activation volume by half.
- Additional conv layer at the beginning (7x7 conv in stem)
- No FC layers at the end (only FC 1000 to output classes)
- (In theory, you can train a ResNet with input image of variable sizes)
-
For deeper networks(ResNet-50+): use bottleneck layer to improve efficiency (similar to GoogLeNet)
e.g.[(28x28x256 INPUT)-(1x1 CONV, 64)-(3x3 CONV, 64)-(1x1 CONV, 256)-(28x28x256 OUTPUT)] - Training ResNet in practice:
- Batch Normalization after every CONV layer
- Xavier initialization from He et al.
- SGD + Momentum (0.9)
- Learning rate: 0.1, divided by 10 when validation error plateaus
- Mini-batch size 256
- Weight decay of 1e-5
- No dropout used
- Experimental Results:
- He et al., 2015
- Able to train very deep networks without degrading (152 layers on ImageNet, 1202 on Cifar)
- Deeper networks now achieve lower training error as expected
- Swept 1st place in all ILSVRC and COCO 2015 competitions
- ILSVRC 2015 classification winner (3.6% top 5 error); better than human performance!
- Details:
- Very deep networks using residual connections
- 152-layer model for ImageNet
- ILSVRC’15 classification winner(3.57% top 5 error)
- Swept all classification and detection competitions in ILSVRC’15 and COCO’15