cs224n - Lecture 4. Dependency Parsing
Two views of linguistic structure: Phrase structure
-
Constituency = phrase structure grammar = context-free grammers(CFGs)
Phrase structure organizes words into nested constituents -
Starting unit: words (noun, preposition, adjective, determiner, …)
the, $\ $ cat, $\ $ cuddly, $\ $ by, $\ $ door -
Words combine into phrases
the cuddly cat(noun phrase),
by the door(prepositional phrase; preposition(by) + noun phrase) -
Phrases can combine into bigger phrases
the cuddly cat by the door(noun phrase) - Lexicon:
$\text{N} \rightarrow \text{cat}$
$\text{N} \rightarrow \text{door}$
$\text{Det} \rightarrow \text{the}$
$P \rightarrow \text{by}$
$\text{Adj} \rightarrow \text{cuddly}$
$\vdots$ - Grammar:
$\text{NP} \rightarrow \text{Det } \ \text{ (Adj)}^{\ast} \ \text{ N } \ \text{ (PP)}$
$\text{PP} \rightarrow \text{P } \ \text{ NP}$
$\vdots$
Two views of linguistic structure: Dependency structure
- Dependency structure shows which words depend on (modify, attach to, or are arguments of) which other words.
Why do we need sentence structure?
- Humans communicate complex ideas by composing words together into bigger units to convey complex meanings
- Listeners need to work out what modifies attaches to what
- A model needs to understand sentence structure in order to be able to interpret language correctly
Ambiguities
- Prepositional phrase ambiguity
- A key parsing decision is how we ‘attach’ various constituents
- PPs, adverbial or participial phrases, infinitives, coordinations
e.g.
\(\begin{align*} \text{The board approved [its acquisition]} & \text{[by Royal Trustco Ltd.]} \\ & \text{[of Toronto]} \\ & \text{[for \$27 a share]} \\ & \text{[at its monthly meeting].} \end{align*}\)
- PPs, adverbial or participial phrases, infinitives, coordinations
- With a sentence of k prepositional phrases at the end of it, the number of parses is given by the Catalan numbers; $C_n = (2n)!/[(n+1)!n!]$, an exponential series growing as the number of prepositional phrases.
- A key parsing decision is how we ‘attach’ various constituents
-
Coordination scopre ambiguity
e.g. Shuttle veteran and longtime NASA executive__ Fred Gregory appointed to board
$\rightarrow$ 1 or 2 person? -
Adjectival/Adverbial Modifier ambiguity
e.g. Students get first hand job experience - Verb Phrase(VP) attachment ambiguity
e.g. Mutilated body washes up on Rio beach to be used for Olympics beach volleyball
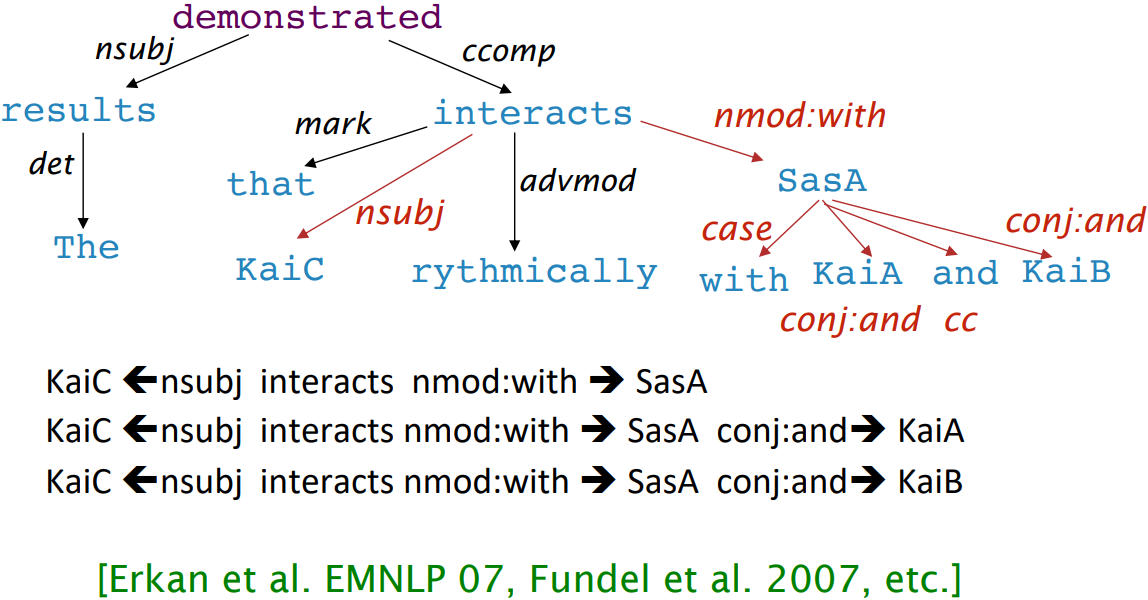
Dependency paths help extract semantic interpretation
- simple practical example: extracting protein-protein interaction
Dependency Grammar and Dependency Structure
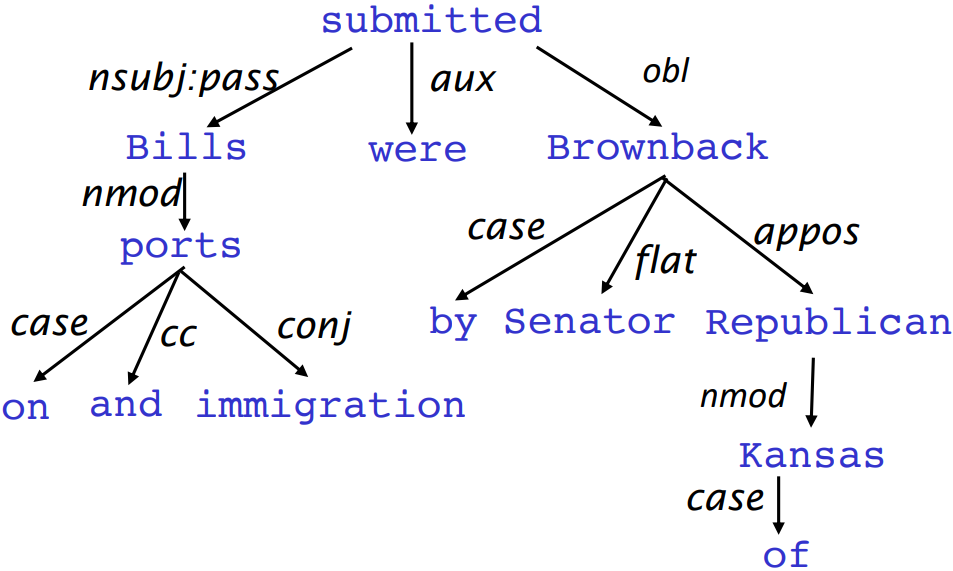
- Dependency syntax postulates that syntactic structure consists of relations between lexical items, normally binary asymmetric relations (“arrows”) called dependencies
-
The arrows are commonly typed with the name of grammatical relations (subject, prepositional object, apposition, etc.)
- An arrow connects a head(governor, superior, regent) with a dependent(modifier, inferior, subordinate)
-
Usually, dependencies form a tree(a connected, acyclic, single-root graph)
-
Check: some people draw the arrows one way; some the other way
- Usually add a fake ROOT so every word is a dependent of precisely 1 other node
The rise of annotated data & Universal Dependencies treebanks
- Advantages of treebank
- Reusability of the labor
- Many parsers, part-of-speech taggers, etc. can be built on it
- Valuable resource for linguistic
- Broad coverage, not just a few intuitions
- Frequencies and distributional information(statistics)
- A way to evaluate NLP systems
- Reusability of the labor
Dependency Conditioning Preferences

- The sources of information for dependency parsing
- Bilexical affinities: The dependency $\text{discussion}\rightarrow\text{issues}$ is plausible
- Dependency distance: Most dependencies are between nearby words
- Intervening material: Dependencies rarely span intervening verbs or punctuation
- Valency of heads: How many dependents on which side are usual for a head?
Dependency Parsing
- A sentence is parsed by choosing for each word what other word (including ROOT) it is a dependent of
- Usually some constraints:
- Only one word is a dependent of ROOT
- Don’t want cycles $A\rightarrow B$, $B\rightarrow A$
- This makes the dependencies a tree
- Final issue is whether arrows can cross(be non-projective) or not
Projectivity
- Definition of a projective parse: There are no crossing dependency arcs when the words are laid out in their linear order, with all arcs above the words
- Dependencies corresponding to a CFG tree must be projective
- i.e., by forming dependencies by taking 1 child of each category as head
- Most syntactic structure is projective like this, but dependency theory normally does allow non-projective structures to account for displaced constituents
- You can’t easily get the semantics of certain constructions right without these nonprojective dependencies
- e.g.
From who did Bill buy the coffee yesterday?
Who did Bill buy the coffee from yesterday
Methods of Dependency Parsing
- Dynamic programming, Eisner(1996): $O(n^3)$ complexity
- Graph algorithms, McDonald et al.(2005): creating a Minimun Spanning Tree
- Constraint Satisfaction, Karlsson(1990)
- “Transition-based parsing” or “deterministic dependency parsing”
Greedy choice of attachments guided by good machine learning classifiers
E.g., MaltParser, Nivre et al.(2008)
Greedy transition-based parsing, Nivre 2003
- A simple form of greedy discriminative dependency parser
- The parser does a sequence of bottom-up actions
- Roughly like “shift” or “reduce” in a shift-reduce parser, but the “reduce” actions are specialized to create dependencies with head on left or right
- The parser has:
- a stack $\sigma$, written with top to the right
- which starts with the ROOT symbol
- a buffer $\beta$, written with top to the left
- which starts with the input sentence
- a set of dependency arcs A
- which starts off empty
- a set of actions
- a stack $\sigma$, written with top to the right
Basic transition-based dependency parser
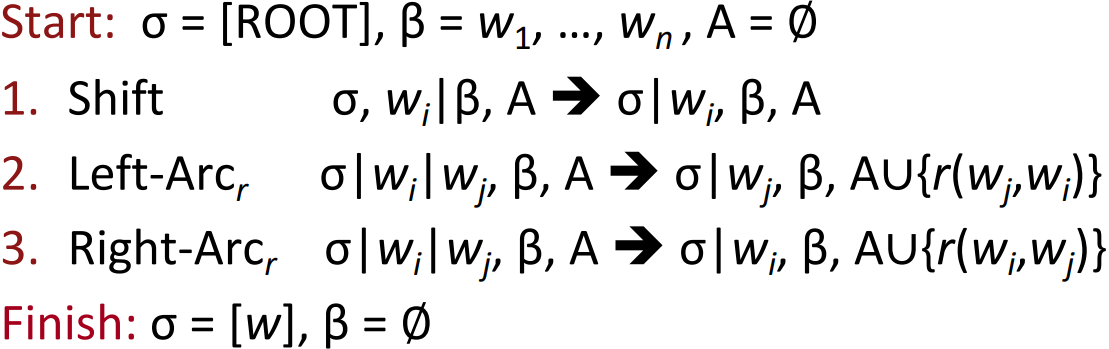
- Arc-standard transition-based parser
E.g., Analysis of “I ate fish”
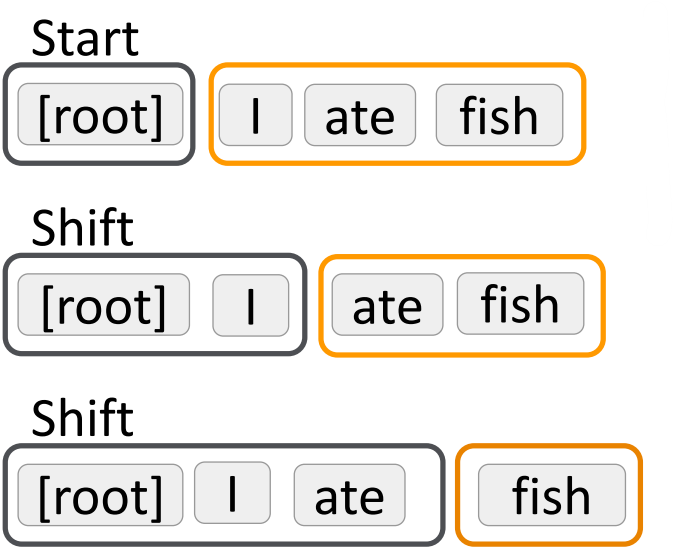
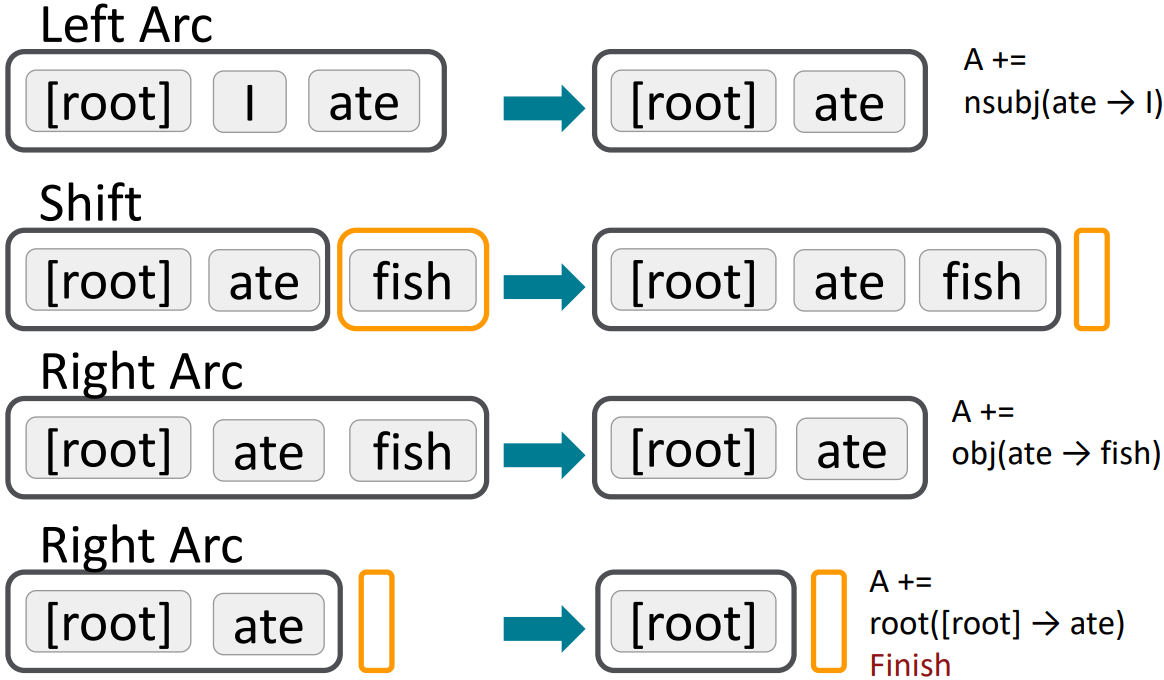
MaltParser, Nivre and Hall 2005
- How we choose the next action?
Answer: Machine Learning! - Each action is predicted by a discriminative classifier (e.g., softmax classifier) over legal move
- Max of 3 untyped choices; max of $\lvert R \rvert \times 2 + 1 $ when typed
- Features: top of stack word, POS; first in buffer word, POS; etc.
- There is NO search(in the simplest form)
- But you can profitably do a beam search if you wish(slower but better): You keep k good parse prefixes at each time step
- The model’s accuracy is fractionally below the state of the art in dependency parsing, but it provides very fast linear time parsing, with high accuracy, great for parsing the web
Conventional Feature Representation
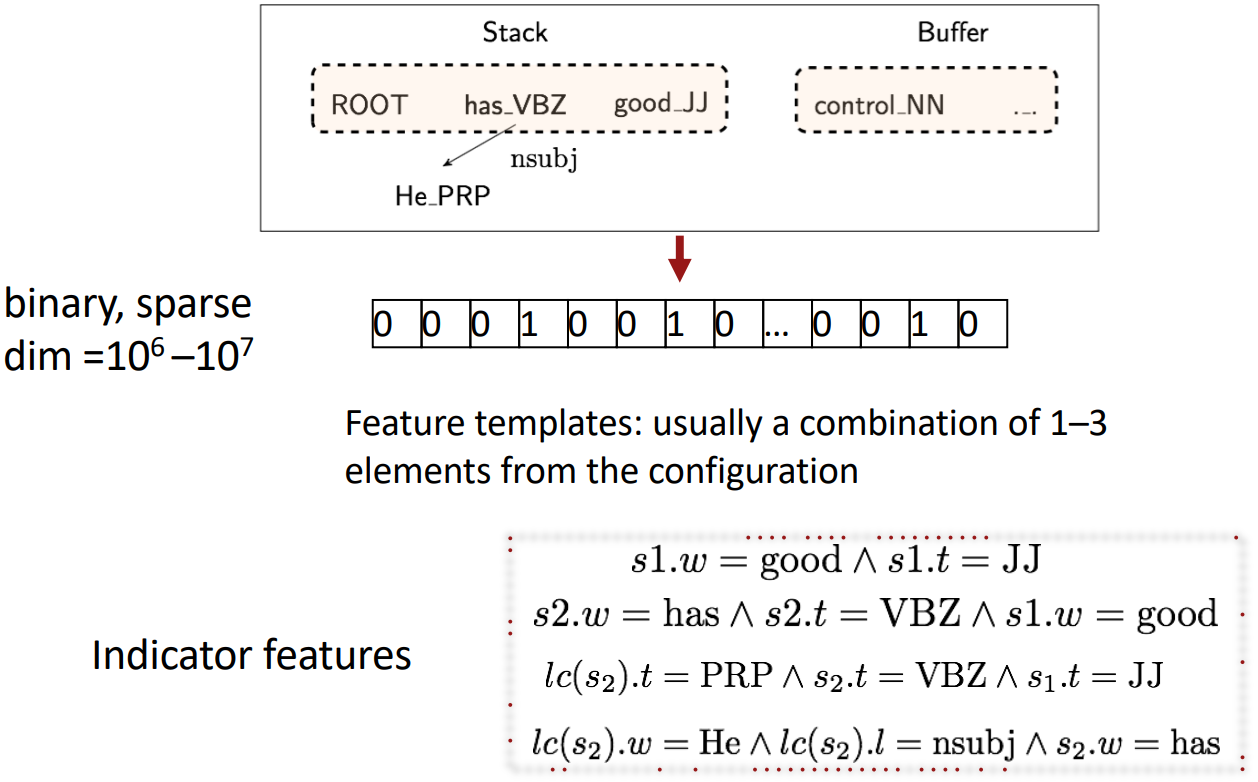
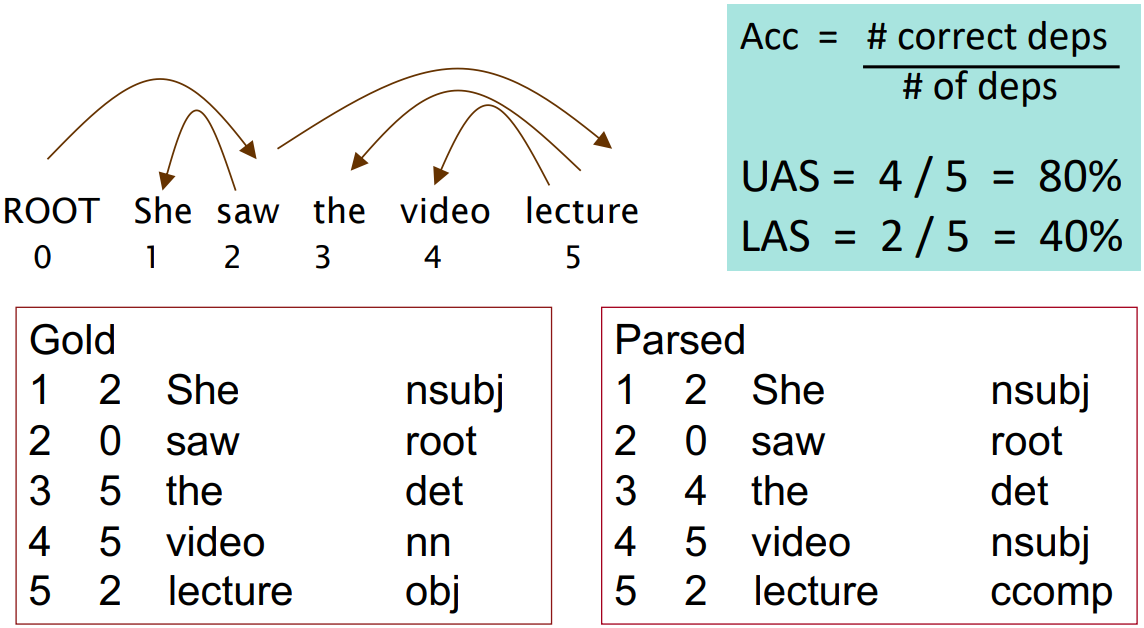
Evaluation of Dependency Parsing: (labeled) dependency accuracy